

Матриця Рамсфелда як ефективний інструмент в процесі приняття рішень
Під час брифінгу, присвяченого війні в Іраку, Дональд Рамсфелд поділив інформацію на 4 категорії: відоме знане, відоме незнане, невідоме знане, невідо...
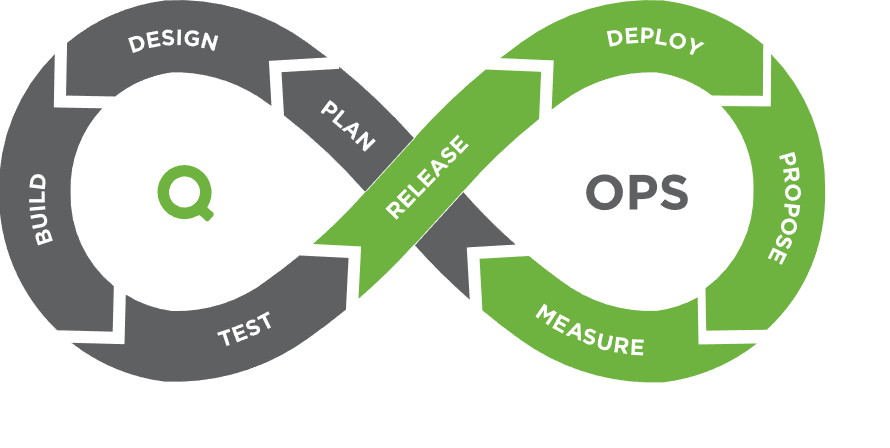
Безперервна інтеграція (СI – Continuous Integration) та безперервна доставка (CD – Continuous Delivery) є однією з типових практик DevOps, що дозволяє розробникам надійно та оперативно розгортати зміни програмного забезпечення. Ключова відмінність від ручної розробки полягає саме в автоматизації тестування та складання коду.
Довгий час, через відсутність у екосистемі Qlik інструментів повноцінного вилучення вихідного коду програми та відповідного автоматичного його складання з вихідних кодів, практика впровадження підходу CI/CD була недоступна для розробки та ефективного управління проєктами на основі технологій Qlik.
Утиліта QOps відкриває такі можливості і для Qlik-розробників, які раніше були доступні іншим розробникам, що використовують Git-репозиторій для зберігання вихідних кодів і налаштовані ранери для автоматичних тестів і розгортання.
Розглянемо детальніші основні аспекти концепції CI/CD як практики DevOps
Безперервна інтеграція. У процесі розробки програм розробником регулярно вносяться зміни, які завантажуються в репозиторій. Автоматичне тестування та перевірка забезпечується завдяки спеціальним інструментам (наприклад, події), зі свого боку, ініціалізуючи інтеграцію як процес, що складається з набору етапів та кроків. Виконання кожного кроку супроводжується логуванням, у якому зображуються зміни.
Безперервна доставка забезпечує автоматизацію розгортання в будь-якому середовищі (продакшн, тестування, середовище розробки). Завдяки автоматичному процесу тестування та розгортання розробник має можливість приділити увагу покращенню програмного забезпечення.
Перевага CI/CD полягає у скороченні часових витрат на розробку програмного продукту, мінімізації та виявленні помилок та дефектів на ранніх етапах створення коду, скороченні часу на виправлення помилок, скорочення циклів зворотного зв’язку.
Наприклад, є сайт, що відображає аналітику продажу деякої компанії. Архітектура цього рішення включає бекенд (може бути представлений базою даних з певним ETL-процесом для обробки даних) та фронтенд (у разі використання технології Qlik – фронтенд забезпечується встановленим веб-сервером). У процесі розробки та оновлень окремими розробниками вносяться зміни до однієї або до кількох частин. Потім зміни об’єднуються в репозиторії лише на рівні вихідних кодів, проходять весь пайплайн і, зрештою, зміни відображаються відразу у всьому продукті.
Етапи циклу CI/CD:
Використання QOps у життєвому циклі розробки Qlik-додатку
Зазвичай автоматизація процесів інтеграції та розгортання виконується встановленим GitHub/GitLab ранером, який інтегрований із репозиторієм. Інструменти автоматизації Bitbucket також можуть інтегруватися з трекінговою системою Jira, що спрощує процес управління завданнями, дає можливість бачити в якій галузі репозиторія знаходиться потрібне оновлення і стежити за подальшим його просуванням. Для отримання команд від ранера QOps має бути встановлений на одному з ним сервері. Це дає можливість включати команди QOps у пайплайн інтеграції та розгортання програм Qlik.
Переваги використання QOps:
Приклад застосування QOps у пайплайні інтеграції та розгортання комплексного Qlik-додатку
Для автоматизації процесів підтримки та оновлення комплексного Qlik-додатку одного з клієнтів компанії за допомогою GitHub Actions інтегровано наступний пайплайн.
Qlik-додаток має 4-х шарову структуру (трансформери – модель – дашборд – екстрактори) та виконано в архітектурі QlikView.
Пайплайн побудований таким чином, що етап його виконання визначається ім’ям гілки Git-репозиторію, в якій відстежуються всі зміни.
Нижче наведено активні етапи, які будуть виконані у разі використання гілки з ім’ям UAT-*. Завдання такого підходу вже під час створення нової гілки підготувати необхідні файли в окремій папці для пробного розгортання нового завдання.
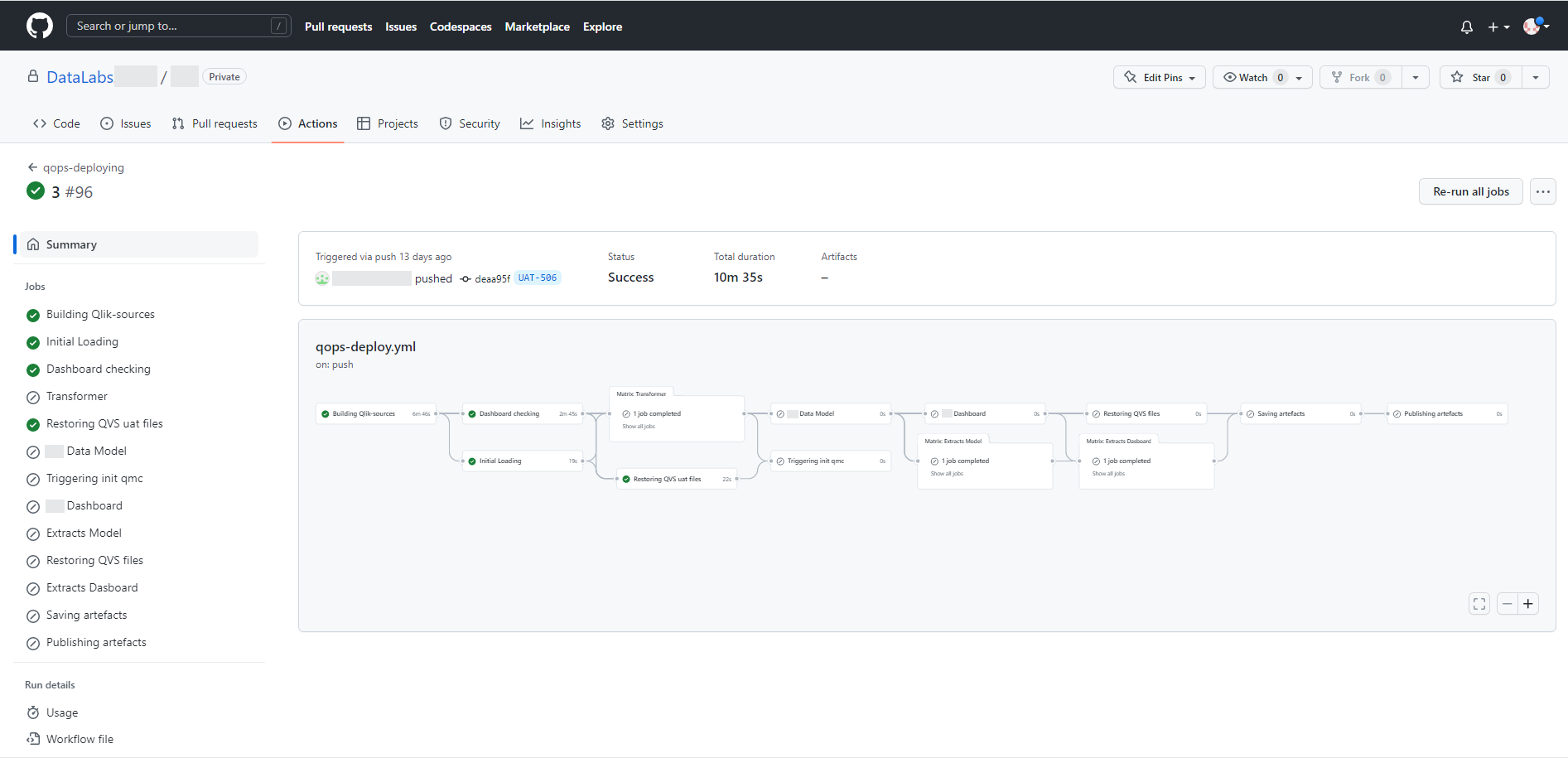
Після підтвердження виконання завдання виконується зведення поточної розробки з основною гілкою репозиторію та ініціалізується виконання всіх етапів процесу. При цьому в пайплайні використовується логіка відбору тільки тих файлів програми, які були змінені, і ці файли переносяться в задане оточення, наприклад продакшн.
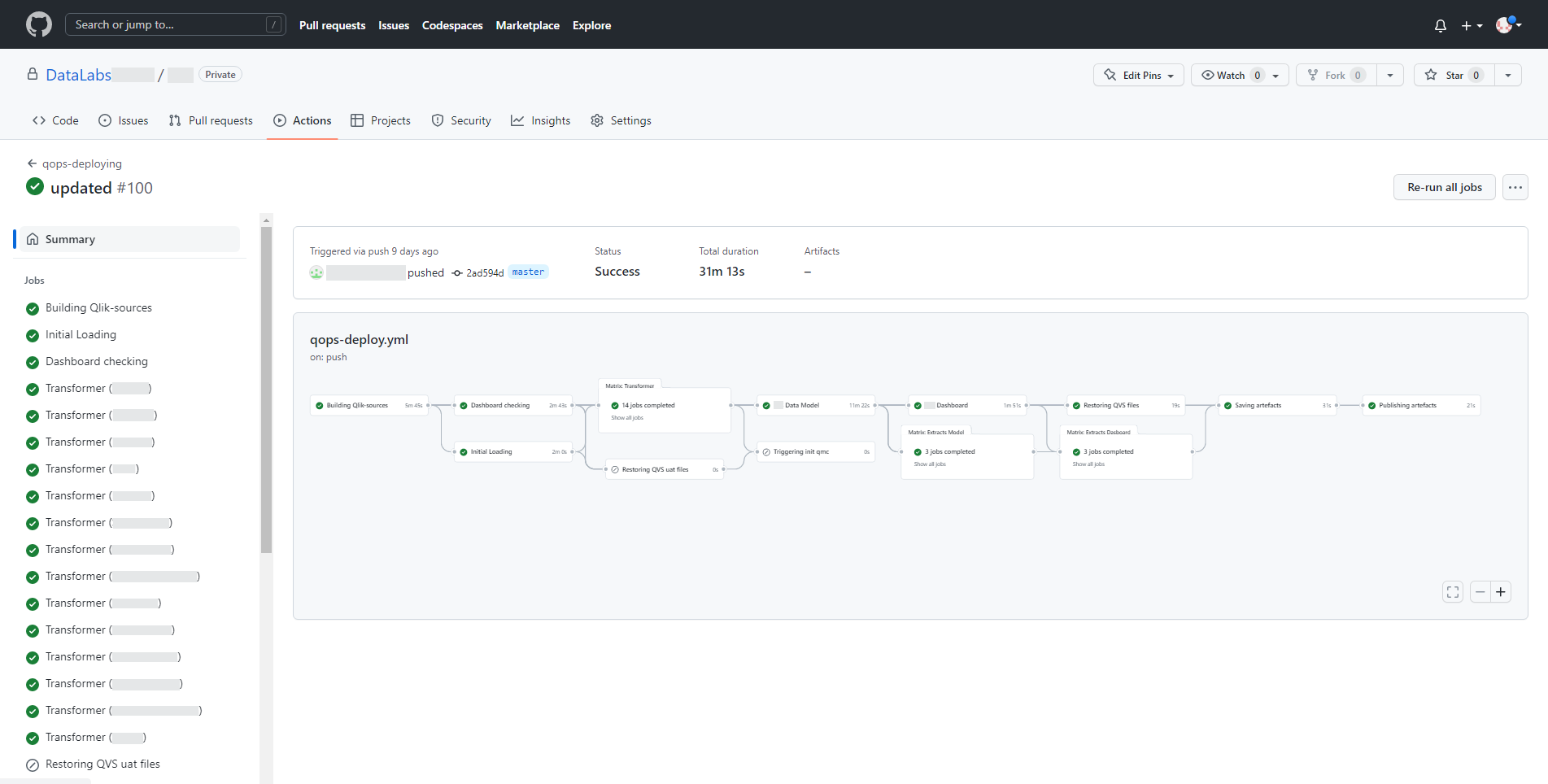
Процес розробки самого пайплайна значно спрощує функціональна можливість ранера як використання матричних операцій до списку додатків одного типу. Таким підходом зручно обробляти трансформери, які мають схожу структуру та призначення.
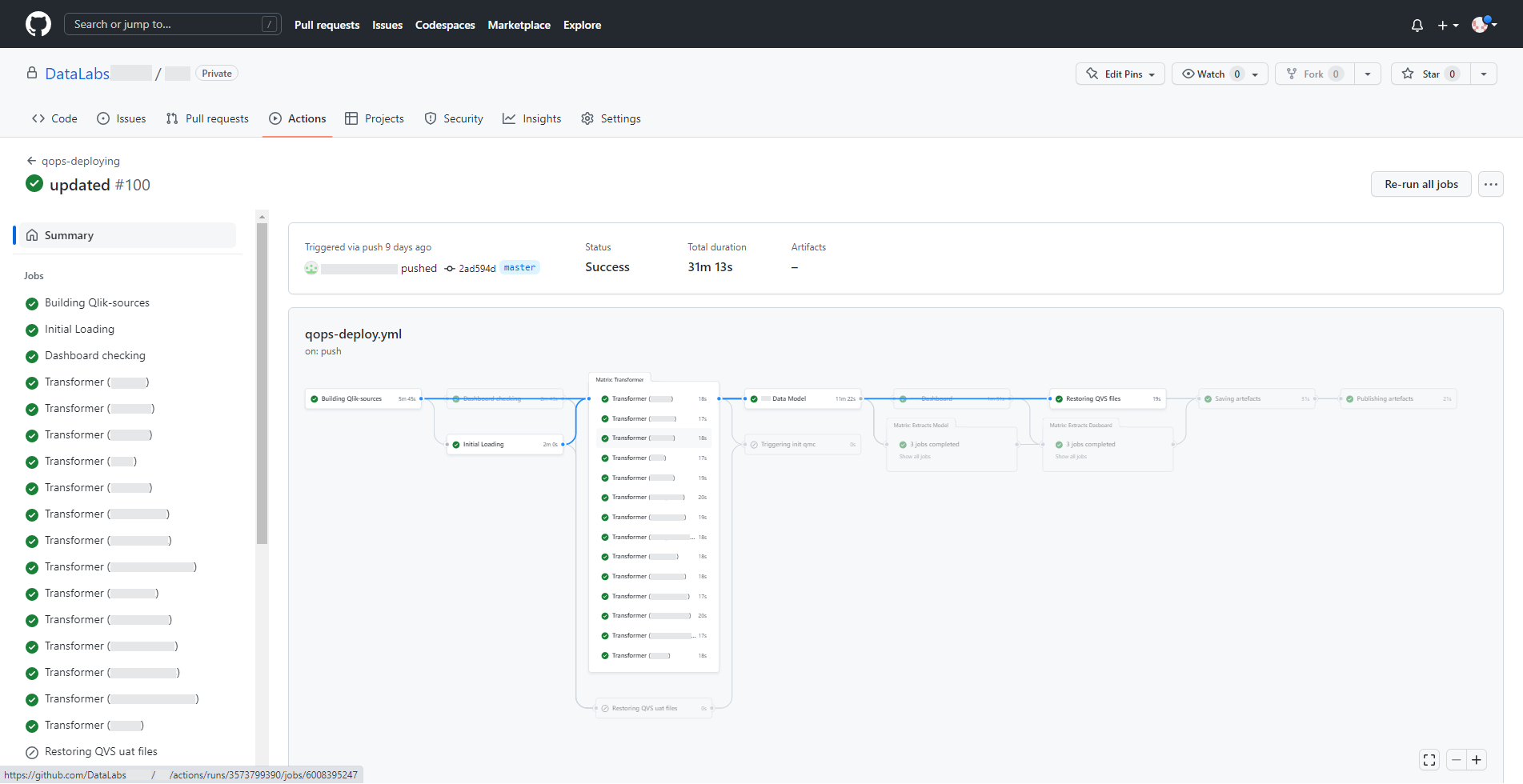
Такий результат виконання послідовних кроків пайплайна в межах одного етапу. Деякі кроки, залежно від поставлених умов, також можуть бути пропущені, ігноровані або зупинені у разі виявлення помилок.
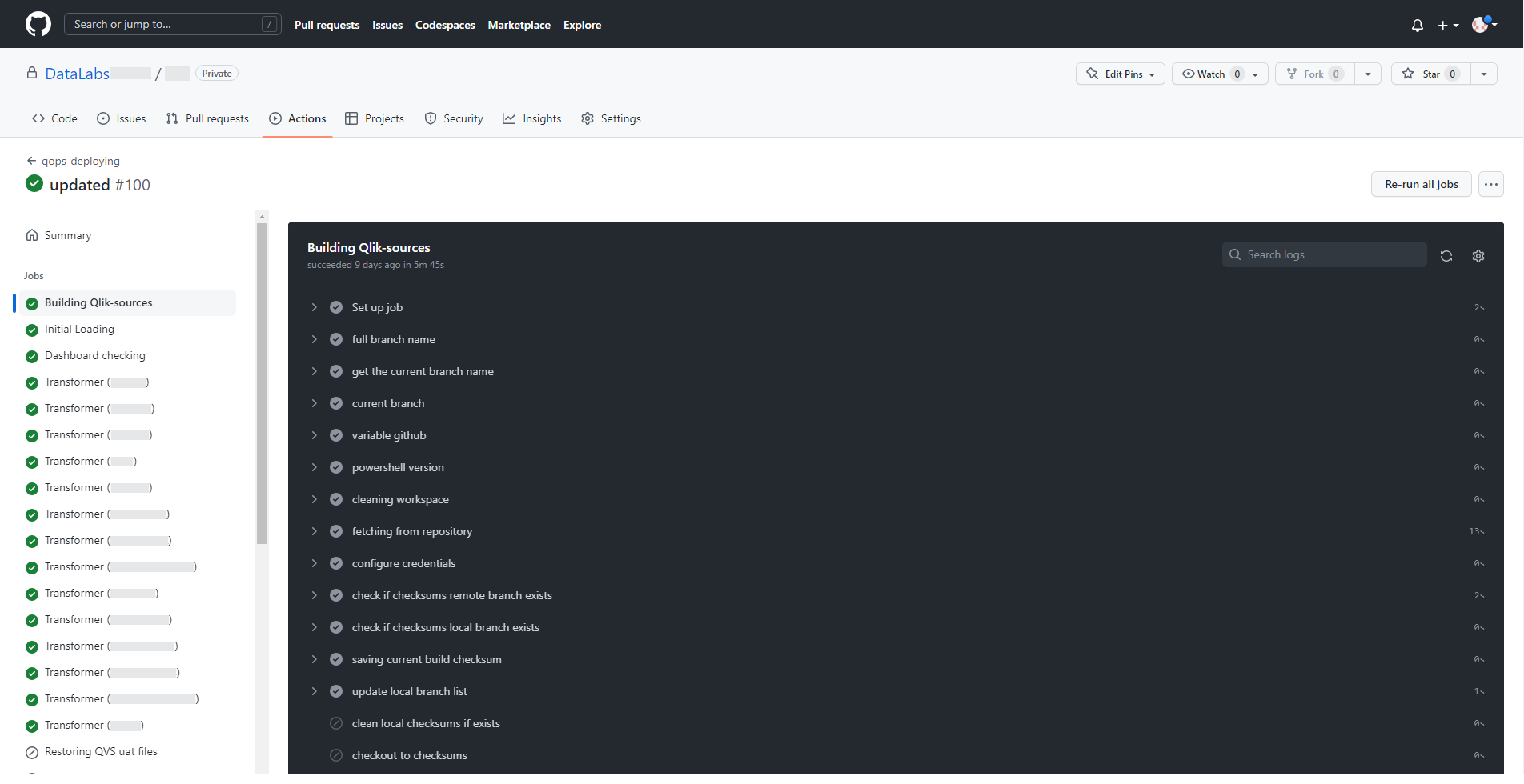
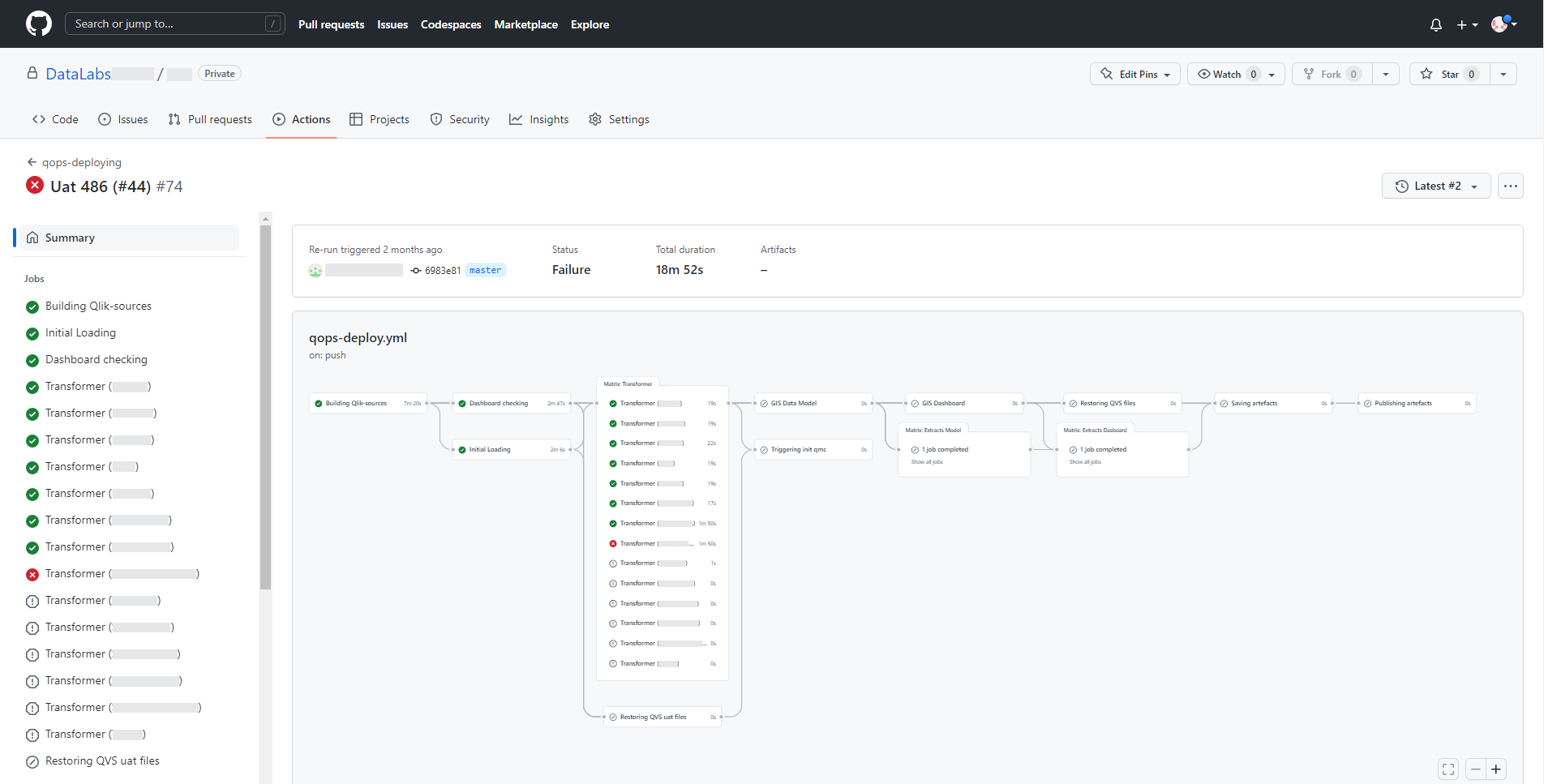
У разі виникнення помилки виконання пайплайн сигналізуватиме про це наступним чином.
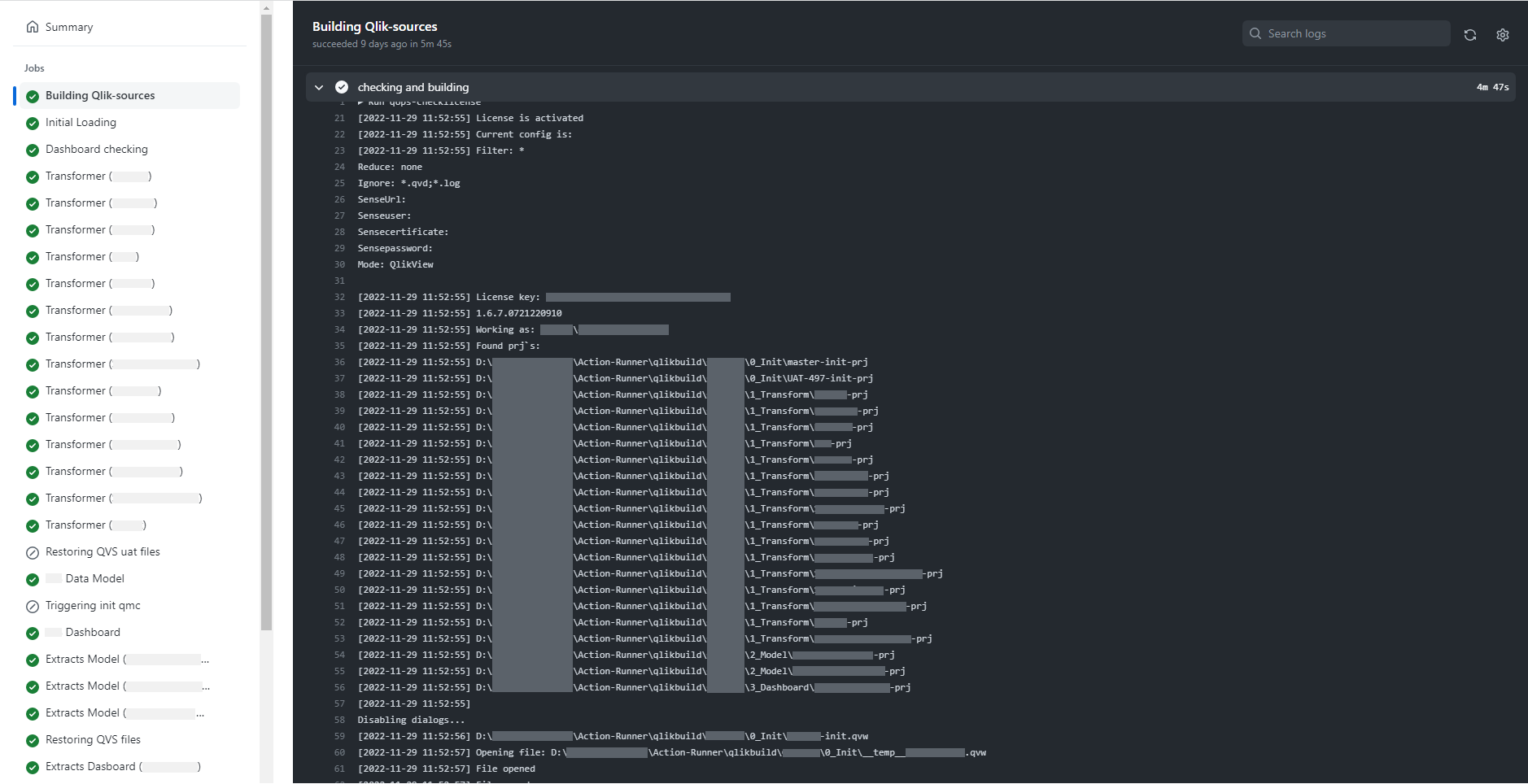
Для більш детального вивчення кожного кроку виконання на кожному етапі доступний консольний висновок, завдяки якому зручно відстежувати і усувати помилки.
Отже, варто зазначити, що впровадження CI/CD у процес розробки та підтримки Qlik-додатку скоротило витрачений час на зведення результатів паралельної розробки та значно спростило процес підготовки додаткових файлів для подальшого розгортання.
Більше інформації про QOps за посиланням
Під час брифінгу, присвяченого війні в Іраку, Дональд Рамсфелд поділив інформацію на 4 категорії: відоме знане, відоме незнане, невідоме знане, невідо...

Штучний інтелект та машинне навчання сприяли просуванню науки про дані. Ці технології допомагають фахівцям з даних проводити аналіз, будувати прогнози...

Штучний Інтелект широко використовується у багатьох додатках, зокрема й для аналітики даних. В основному ШІ застосовується для аналізу великих наборів...
Коментарів поки немає.
Залишити коментар