Кожен шар у вашому дата-стеку має CI/CD. Крім одного.
Код застосунків живе в Git. Інфраструктура описана в Terraform. Дата-пайплайни проходять через dbt з pull request-ами і тестами. ML-моделі відстежуються в MLflow з номерами версій і логами експериментів.
А потім є BI-шар: Qlik, Tableau, Power BI. Де бізнес-критичні дашборди деплоять так: хтось експортує файл, перейменовує його і імпортує на інший сервер. Де «план відкату» означає надію, що хтось зберіг копію перед п’ятничними змінами. Де «що змінилось у Sales Dashboard цього тижня?» означає знизування плечима і Slack-тред, який нікуди не веде.
Довгий час це було нормально. BI був у кінці ланцюжка даних. На виході був графік на екрані, який споживала людина, здатна помітити, коли щось виглядає не так, і запитати про це. Планка надійності була низькою, бо радіус ураження був обмеженим.
Це змінюється.
Раніше Qlik-застосунки були кінцевою зупинкою. Людина дивилась на дашборд, приймала рішення, йшла далі. Але дедалі частіше споживачами BI-виводу є не люди – а системи.
Подивіться, що відбувається прямо зараз у підприємствах, які використовують Qlik:
Коли дашборд ламається в старому світі, хтось помічає, що графік виглядає неправильно, і створює тікет. Коли Qlik-застосунок ламається в новому світі, AI-система приймає погане рішення, бо дані під нею змінились, і ніхто цього не позначив, не переглянув і не затвердив.
Планка надійності для BI-шару щойно піднялася. Тихо, без офіційного оголошення.
Qlik Sense зберігає застосунки як .qvf файли – непрозорі бінарні контейнери. Їх неможливо відкрити в текстовому редакторі. Неможливо порівняти дві версії. Неможливо побачити, що змінилось між вівторковим і середовим застосунком, без декомпозиції на складові частини, що не є вбудованою функцією.
Це створює набір конкретних проблем, які наростають з масштабом:
Немає діфу. Якщо розробник змінює set-вираз у master measure, і ця міра використовується в 14 графіках на 3 аркушах, немає нативного способу побачити, що змінилось, куди це поширюється і яке було попереднє значення.
Немає аудит-трейлу. «Хто змінив формулу Revenue KPI минулого четверга?» – це питання, на яке Qlik Sense не може відповісти з коробки. Можна побачити, що застосунок був змінений, але не що саме було змінено і ким на рівні об’єктів.
Немає відкату. Якщо п’ятничний деплоймент ламає дашборд, від якого залежать 200 користувачів у понеділок вранці, вас чекають великі проблеми. План відновлення ручний: знайти бекап, якщо він існує, імпортувати його, сподіватися, що він достатньо свіжий.
Немає code review. Зміни потрапляють із локальної сесії розробника в продакшн без жодної перевірки іншою людиною. У розробці застосунків це було б немислимо. У BI це стандартна практика.
Ось сценарій, який регулярно повторюється. Qlik-розробник оновлює set-вираз у master measure під назвою «Net Revenue». Зміна виглядає правильно в тесті – перевірка проти одного джерела даних, числа сходяться. Але ця міра використовується в 14 графіках у дашбордах Sales, Finance та Operations. У двох із цих графіків вираз взаємодіє з іншим set analysis clause, що створює тонку помилку в розрахунку. Ніхто не помічає три тижні, поки Finance не позначить розбіжність. На той час ніхто не пам’ятає, що змінилось і коли.
У середовищі з контролем версій ця зміна була б видима в pull request. Друга пара очей побачила б взаємодію. Деплоймент можна було б простежити до конкретного коміту в конкретний час конкретною людиною.
Це не про встановлення плагіна чи додавання кнопки. Версіонування Qlik-застосунків – це архітектурний зсув у тому, як ваша команда працює з аналітичним кодом. Ось як це виглядає на практиці.
Декомпозиція. Файл .qvf розкладається на людино-читабельні файли – YAML і JSON – що представляють окремі об’єкти. Міри, виміри, змінні, load-скрипти, аркуші, графіки. Кожен стає файлом, який можна читати, порівнювати і відстежувати.
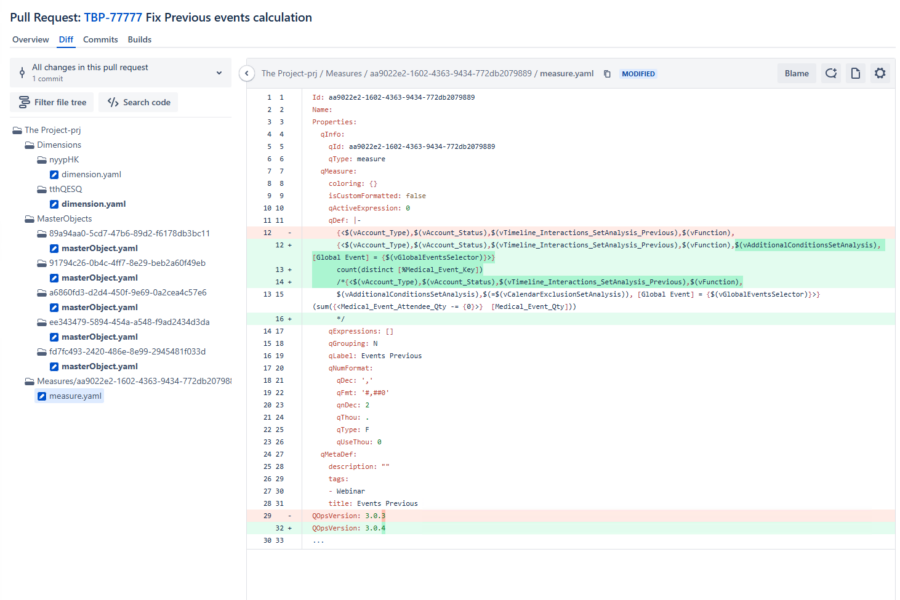
Ось як виглядає реальний pull request у продакшн Qlik-середовищі. Це з реального деплойменту – не демо, не мок-ап:
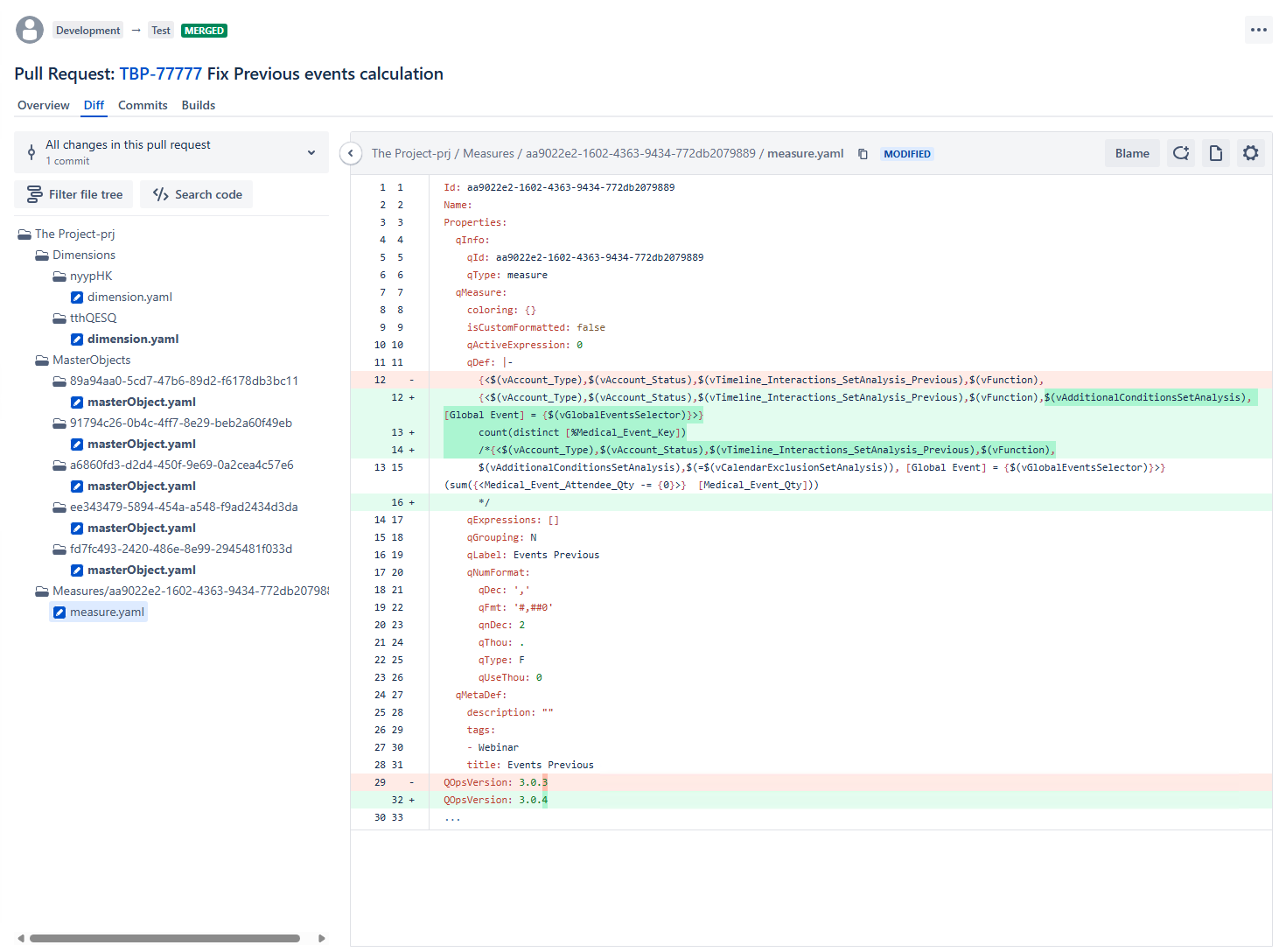
Подивіться на ліву панель. Те дерево файлів – Dimensions, MasterObjects, Measures – це декомпозований Qlik-застосунок. Кожен об’єкт зберігається як окремий YAML-файл, який Git може відстежувати і порівнювати.
Тепер подивіться на праву панель. Розробник змінив set-вираз у мірі «Events Previous». Кольоровий діф показує, що саме відбулось: додано дві нові умови фільтрації до set analysis, введено новий вираз агрегації, а стару версію збережено як коментар для довідки. Інкремент версії з 3.0.3 до 3.0.4 відстежено автоматично.
Це можна переглянути. Це можна перевірити. Другий розробник може подивитись і запитати: «чому ми додаємо фільтр Global Event до цієї міри? Чи впливає це на інші розрахунки, що посилаються на ці змінні?» Це питання задається до того, як зміна потрапляє в продакшн – а не через три тижні, коли хтось помічає розбіжність.
Гілкування. Два розробники можуть працювати з одним застосунком одночасно, не перезаписуючи один одного. Кожен працює у своїй гілці, вносить зміни і зливає через контрольований процес.
Промоція. Зміни рухаються з DEV у TEST у PROD через визначений пайплайн, а не через ручний експорт-імпорт. Кожна промоція – це зафіксована подія з гейтом затвердження.
Зрілий Qlik-пайплайн деплойменту слідує тому самому патерну, що й будь-який інший CI/CD пайплайн. Ось референсна архітектура:
Це не теоретично. Це те, що зрілі Qlik-команди роблять сьогодні. Інструментарій існує і перевірений. Що робить це робочим – не конкретна технологія, а рішення ставитися до Qlik-застосунків з тією ж дисципліною, яку решта стеку вже отримує.
Складніша проблема – не технічна. Інструментарій для контролю версій і CI/CD Qlik існує і працює надійно. Складніша проблема – організаційна.
Більшість Qlik-команд виросли у світі, де «деплой» означало «опублікувати з QMC». Впровадження Git-based воркфлоу означає кілька речей, які дійсно складні:
Навчання розробників Git. Значна частина Qlik-розробників ніколи не працювала з контролем версій. Вони прийшли з бекграунду бізнес-аналітика або дата-аналітика, а не софтверної інженерії. Концепції Git – гілкування, злиття, pull request-и – для них нові. Це вимагає реальних інвестицій у навчання – не одногодинної сесії, а тривалої підтримки протягом тижнів, поки команда набирає впевненості з новими інструментами і процесами.
Створення культури code review. У багатьох BI-командах концепція перегляду вашої роботи іншою людиною перед виходом у продакшн – чужа. Розробники звикли працювати ізольовано з повною автономією. Впровадження code review для аналітичного коду може сприйматися як бюрократія, якщо це не позиціонувати правильно. Фреймінг має значення: це про виловлювання тонких помилок, невидимих для автора коду, а не про уповільнення.
Змусити IT ставитися до Qlik як до інфраструктури застосунків. У багатьох організаціях Qlik знаходиться в сірій зоні між IT і бізнесом. Ним керує BI-команда, а не команда платформної інженерії. Він не отримує ту саму CI/CD інфраструктуру, той самий моніторинг, ту саму дисципліну деплойменту. Зміна цього вимагає від CDO або VP of Analytics довести, що Qlik – це інфраструктура, а не інструмент звітності.
Це момент, де важлива чесність. Цей перехід нетривіальний. Команді з п’яти Qlik-розробників знадобляться тижні, а не дні, щоб адаптувати Git-воркфлоу і набрати впевненості в новому процесі.
Питання в тому, чи вартість невиконання цього переходу – невиявлювані зміни в шарі, від якого тепер залежать AI-навантаження – вища за вартість його виконання. Для більшості організацій з AI-стратегією, що торкається їхнього аналітичного стеку, відповідь стає очевидною.
Практична самооцінка:
Якщо три або більше з цих пунктів не виконуються, ви оперуєте своїм Qlik-середовищем на рівні надійності, нижчому за те, що ваша організація тепер вимагає. Не тому, що ви робите щось неправильно – а тому, що вимоги змінились навколо вас, а інструментарій залишився тим самим.
Інструменти для контролю версій і автоматизації деплойментів Qlik існують сьогодні. Вони не експериментальні. Вони працюють у продакшні на підприємствах, які здійснили цей перехід і ніколи не озирались назад.
Патерни такі самі, як ті, що кожен інший шар дата-стеку прийняв роки тому. Git для контролю версій. Pull request-и для code review. CI/CD пайплайни для автоматизованого деплойменту. Аудит-логи для комплаєнсу.
Єдине, що специфічне для Qlik – це крок декомпозиції: перетворення .qvf бінарників у текстові файли, з якими можуть працювати стандартні інструменти. Як тільки це вирішено, все інше випливає з існуючих DevOps-практик, які ваша організація вже розуміє.
Якщо ваше Qlik-середовище є частиною вашої AI-стратегії – а воно майже напевно є, офіційно чи ні – тоді ставитися до нього як до інфраструктури – це не майбутнє міркування. Це поточна вимога.
Ми створили QOps саме для вирішення цієї проблеми – контроль версій на базі Git та CI/CD для Qlik Sense, Qlik Cloud і QlikView. Якщо ваша команда оцінює цей напрямок, запишіться на 15-хвилинну демонстрацію.

Коментарів поки немає.
Залишити коментар