
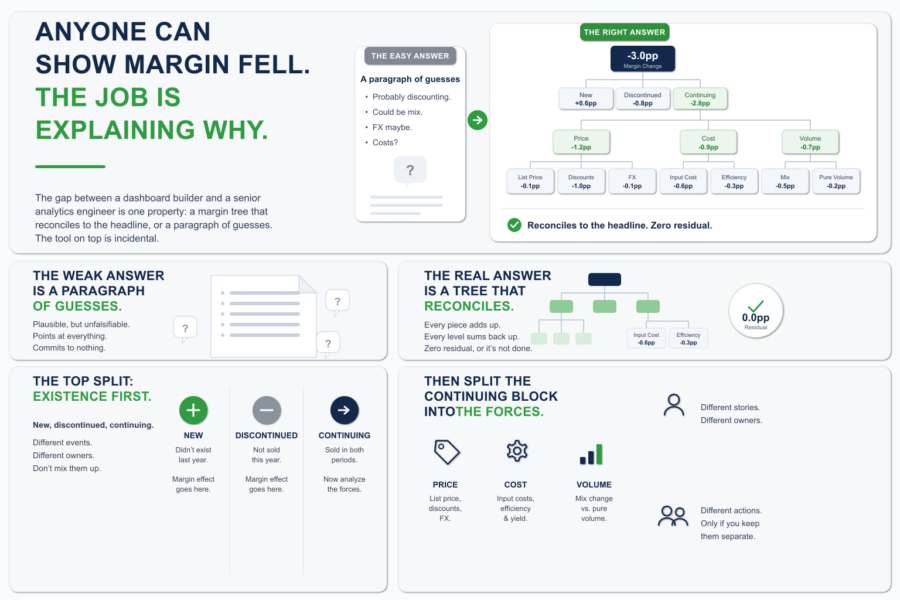
Будь-хто може показати, що маржа впала. Робота — пояснити чому.
Маржа впала на три пункти. CFO це вже знає. Дашборд це показав, борд-дек це показав, число не оскаржується. Те, чого вони хочуть від вас – це на...

Зі зростанням обсягу корпоративних даних паралельно зростає обсяг неструктурованих даних. Їхній обсяг щорічно збільшується зі швидкістю від 55 до 65%. Ігноруючи такі дані, компанії не отримують певних знань і не використовують їх для аналітики, що автоматично не дозволяє використовувати всі існуючі можливості. Проте, дуже важливо знати, як правильно використовувати неструктуровані дані, щоб досягти поставлених бізнес-цілей.
Користь неструктурованих даних:
Використання неструктурованих даних для BI передбачає 3 основні кроки:
Маржа впала на три пункти. CFO це вже знає. Дашборд це показав, борд-дек це показав, число не оскаржується. Те, чого вони хочуть від вас – це на...
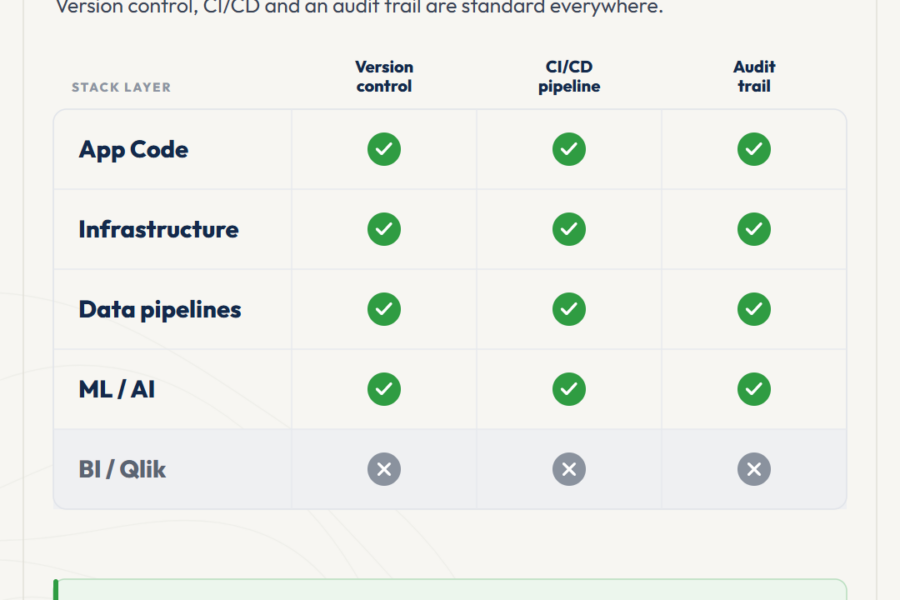
У певний момент кожна BI-команда, яка переростає трьох-чотирьох розробників, стикається з тим самим. Координація деплойментів починає з’їдати час сень...
Екосистема Qlik перебуває на переломному етапі. AI-системи та автоматизовані пайплайни починають споживати аналітичний вивід як вхідні дані, а не прос...
Коментарів поки немає.
Залишити коментар