
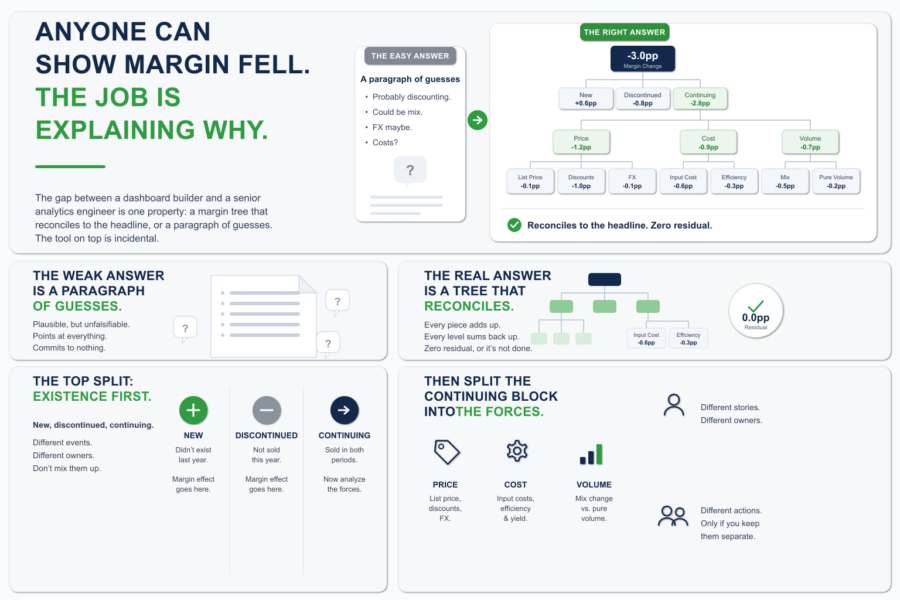
Anyone Can Show Margin Fell. The Job Is Explaining Why.
Margin is down three points. The CFO knows that already. The dashboard told them, the board deck told them, the number is not in dispute. What they wa...
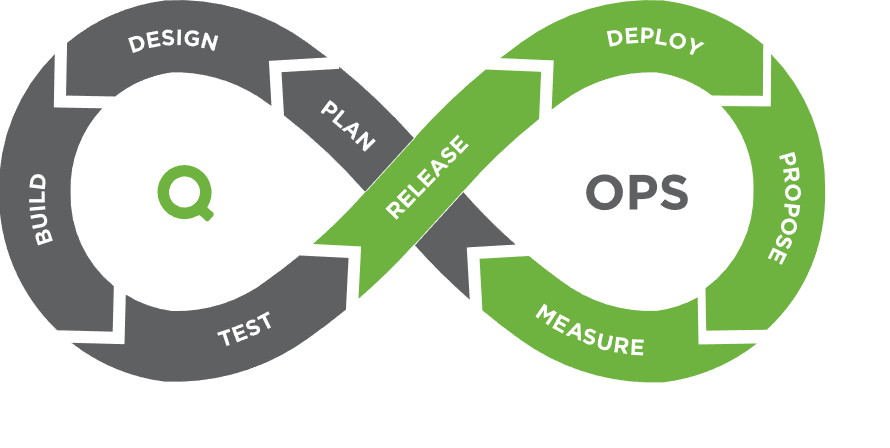
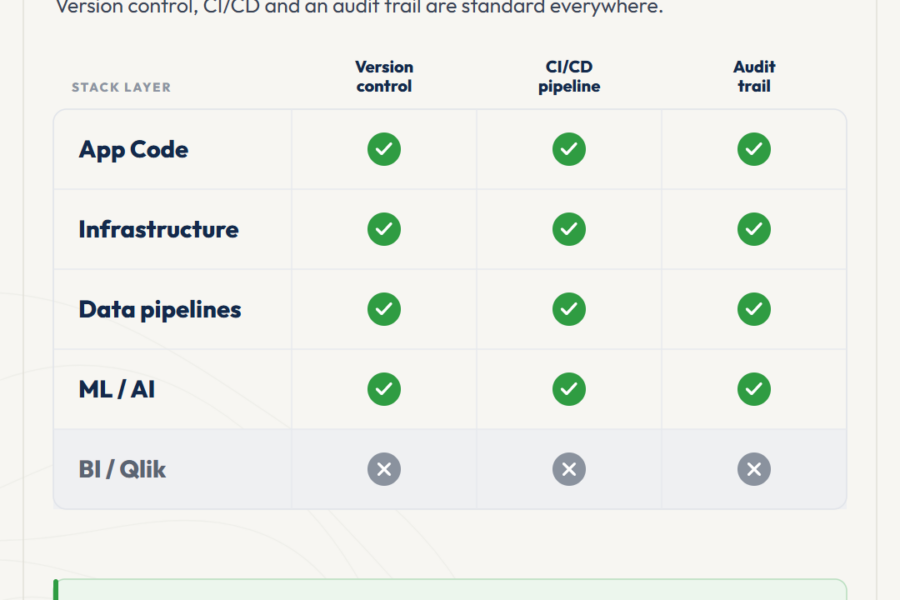
Continuous integration (CI – Continuous Integration) and continuous delivery (CD – Continuous Delivery) are one of the typical DevOps practices that allow developers to deploy software changes reliably and quickly. The key difference from manual development lies precisely in the automation of testing and code assembly.
For a long time, due to tools lack in the Qlik ecosystem for fully extracting application source code and its corresponding automatic assembly from source codes, the practice of CI / CD approach implementation was not available for developing and effectively managing projects based on Qlik technologies.
For Qlik developers QOps utility provides opportunities that were previously available to all other developers using a git repository for storing source codes and configured runners for automated tests and deployment.
Let’s take a look at the main aspects of the concept of CI / CD as a DevOps practice
Continuous Integration. Developer regularly makes changes in the applications development process. And these changes are uploaded to the repository. Automated testing and verification are provided through special tools such as events, that initiate the integration as a process consisting of stages and steps set. The execution of each step is accompanied by logging, that reflects all changes.
Continuous delivery automates deployment in any environment (production, test environment, development environment). Automated testing and deployment process provide developer with opportunity to focus on improving the software.
The advantage of CI/CD is to reduce the time spent on developing a software product, minimizing and identifying errors and defects in the early stages of code creation, reducing the time to correct errors, and reducing feedback cycles.
For example, there is a site that displays sales analytics for a certain company. The architecture of this solution includes a backend (can be represented by a database with a specific ETL process for data processing) and a frontend (in the case of using Qlik technology, the frontend is provided by an installed web server). During development and updates, individual developers make changes to one or both parts. Then changes are merged into the repository at the source code level, go through the entire pipeline and, ultimately, the changes are reflected immediately in the entire product.
CI/CD cycle stages:
Using QOps in the Development Life Cycle of a Qlik Application
Automation of integration and deployment processes is performed by the installed GitHub/GitLab runner, that is integrated with a repository. Bitbucket automation tools can also integrate with the Jira tracking system. It simplifies the task management process, makes it possible to see in which repository branch the desired update is located and follow its further progress. To receive commands from a runner, QOps must be installed on the same server as the runner. This makes it possible to include QOps teams in the integration and deployment pipeline of Qlik applications.
Benefits of using QOps
An example of using QOps in the integration and deployment pipeline of a complex Qlik application
The following pipeline is integrated to automate the processes of supporting and updating complex Qlik application of one of company’s clients using GitHub Actions.
Qlik application has a 4-layer structure (transformers – model – dashboard – extractors) and is made in QlikView architecture.
The pipeline is built in such a way that the stages of its execution are determined by the name of Git repository branch. All changes are tracked there.
Below are the active steps that will be executed if a branch named UAT-* is used. The task of this approach is to prepare the necessary files in a separate folder for the trial deployment of a new task when creating a new branch.
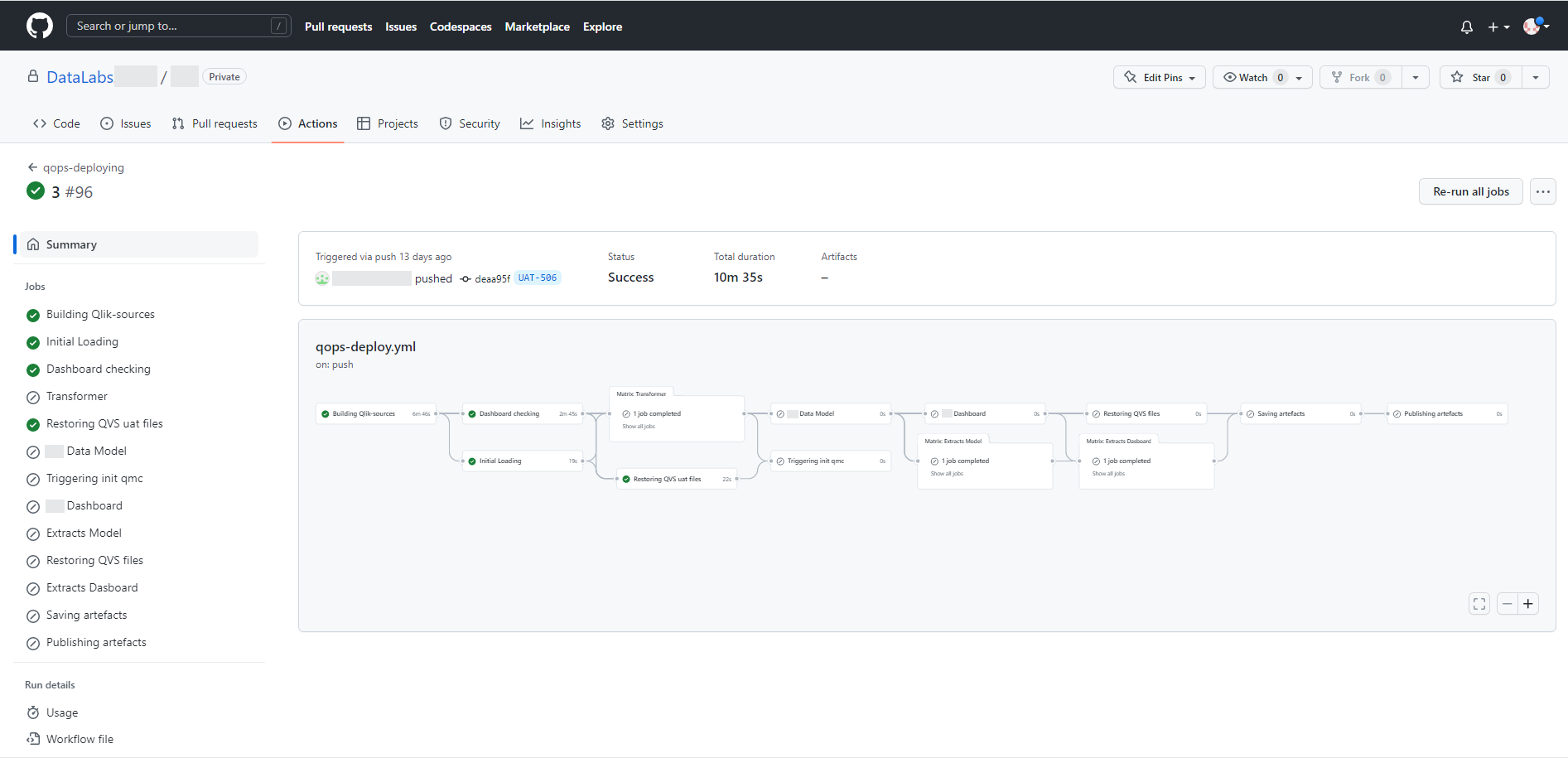
After confirming task completion current development is merged with the main repository branch and execution of all process stages is initialized. At the same time, the pipeline uses the logic of selecting only those application files that have been changed. These files are transferred to a given environment, for example, to production.
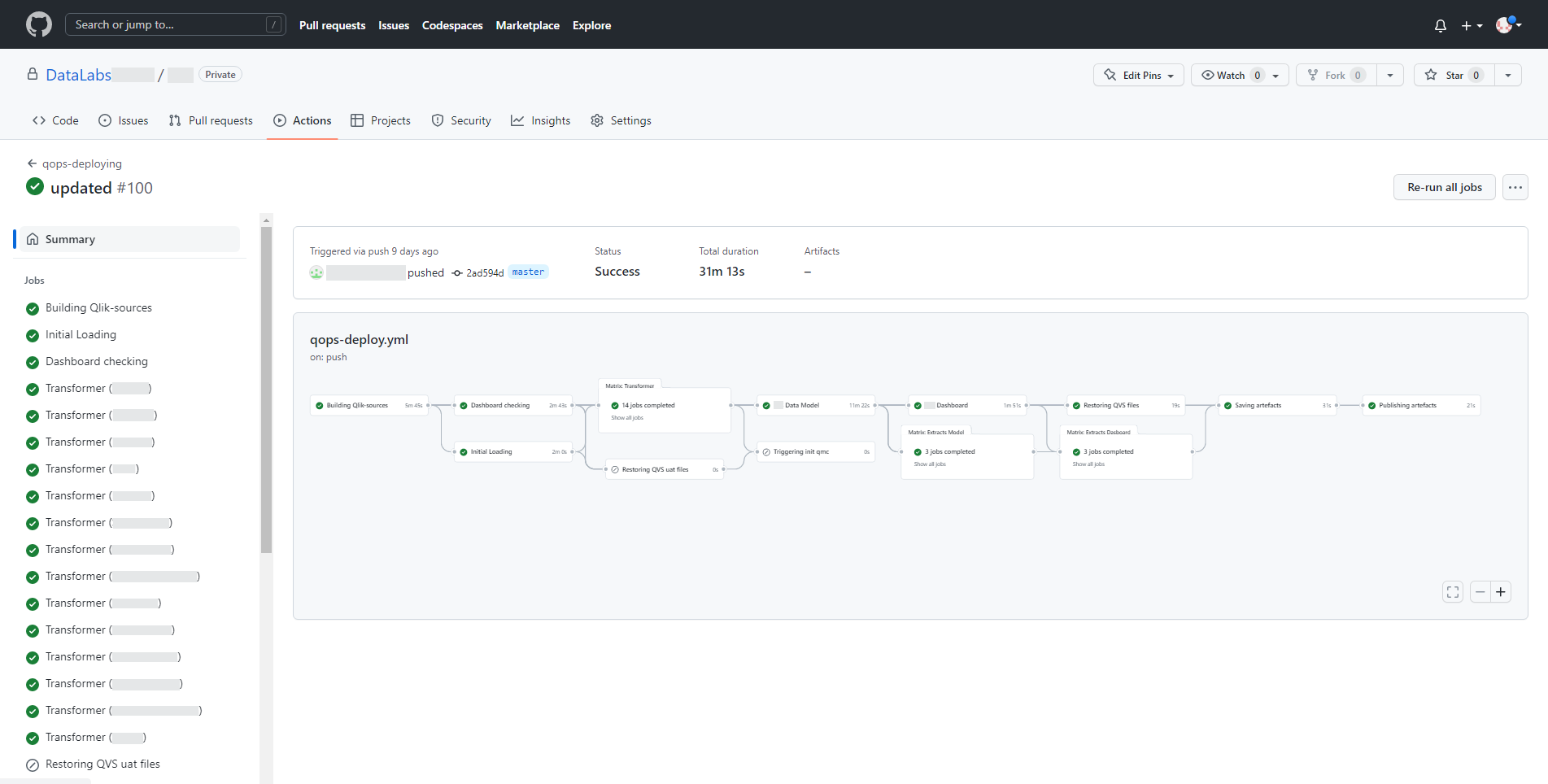
Development process of the pipeline greatly simplifies runner functionality in the form of using matrix operations on a list of same type applications. This approach is convenient to process transformers that have a similar structure and purpose.
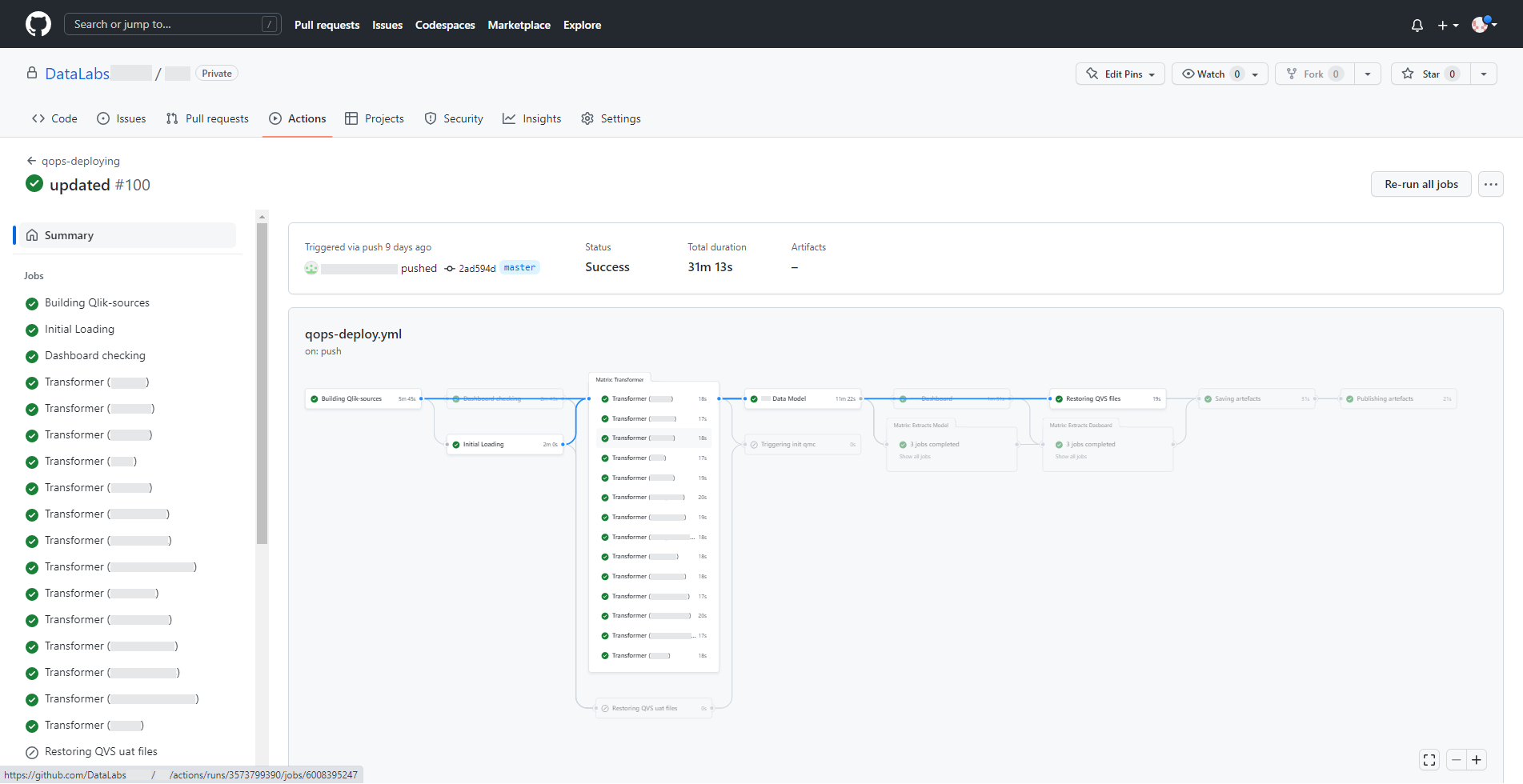
This is how the result of executing successive pipeline steps within one stage looks like. Some steps depending on the conditions set can also be skipped, ignored, or stopped if errors are found.
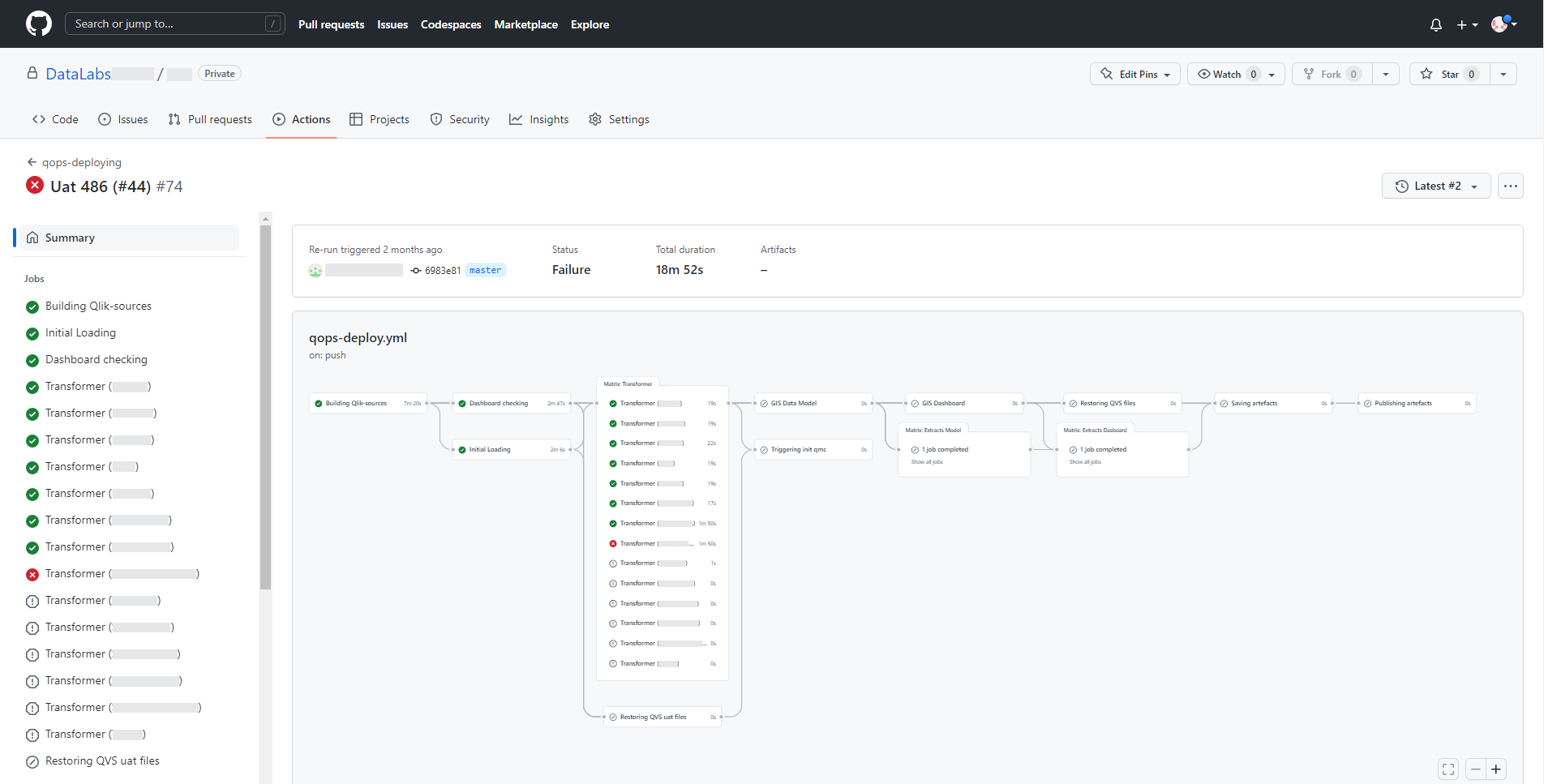
In case of a runtime error, the pipeline will signal it as follows.
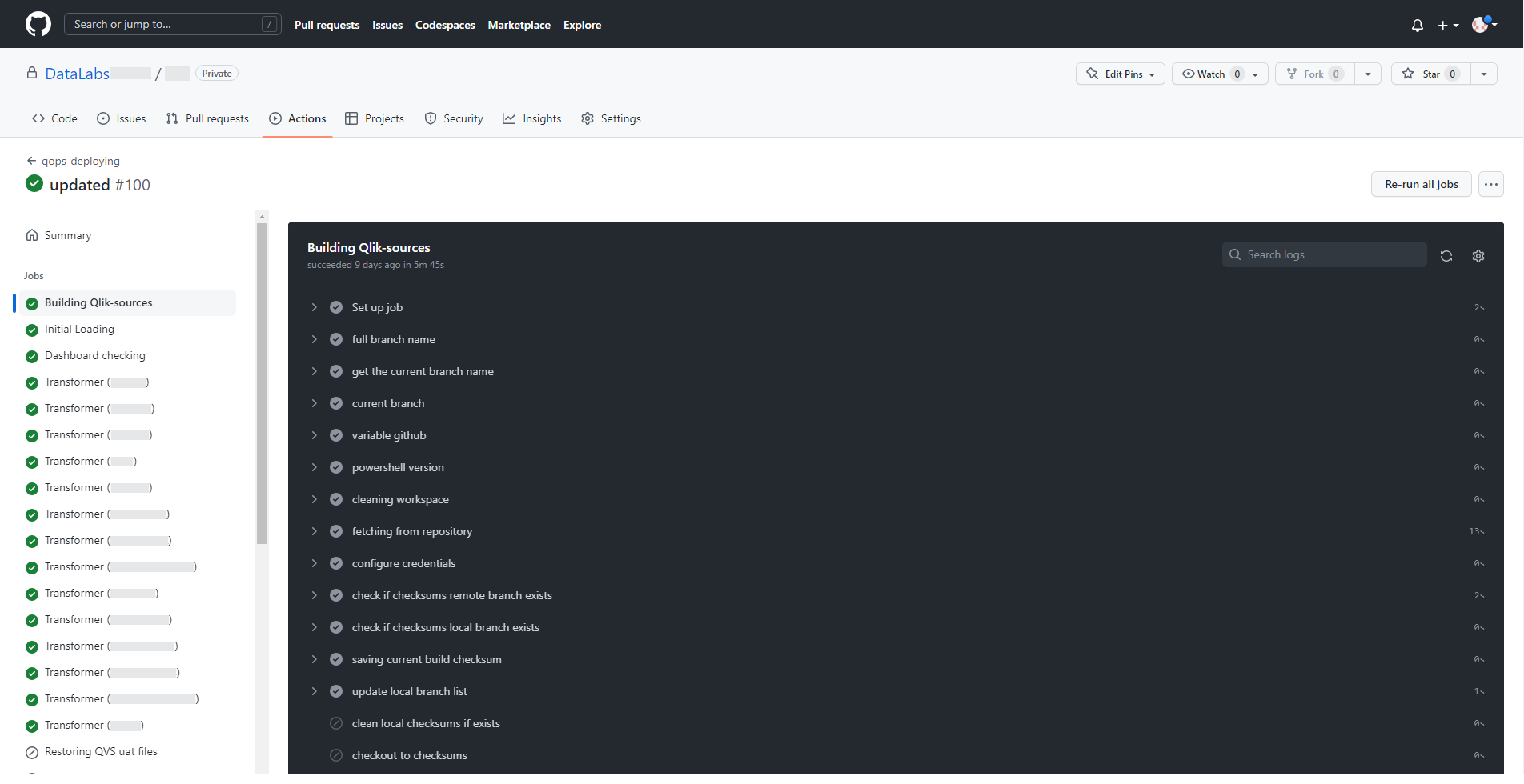
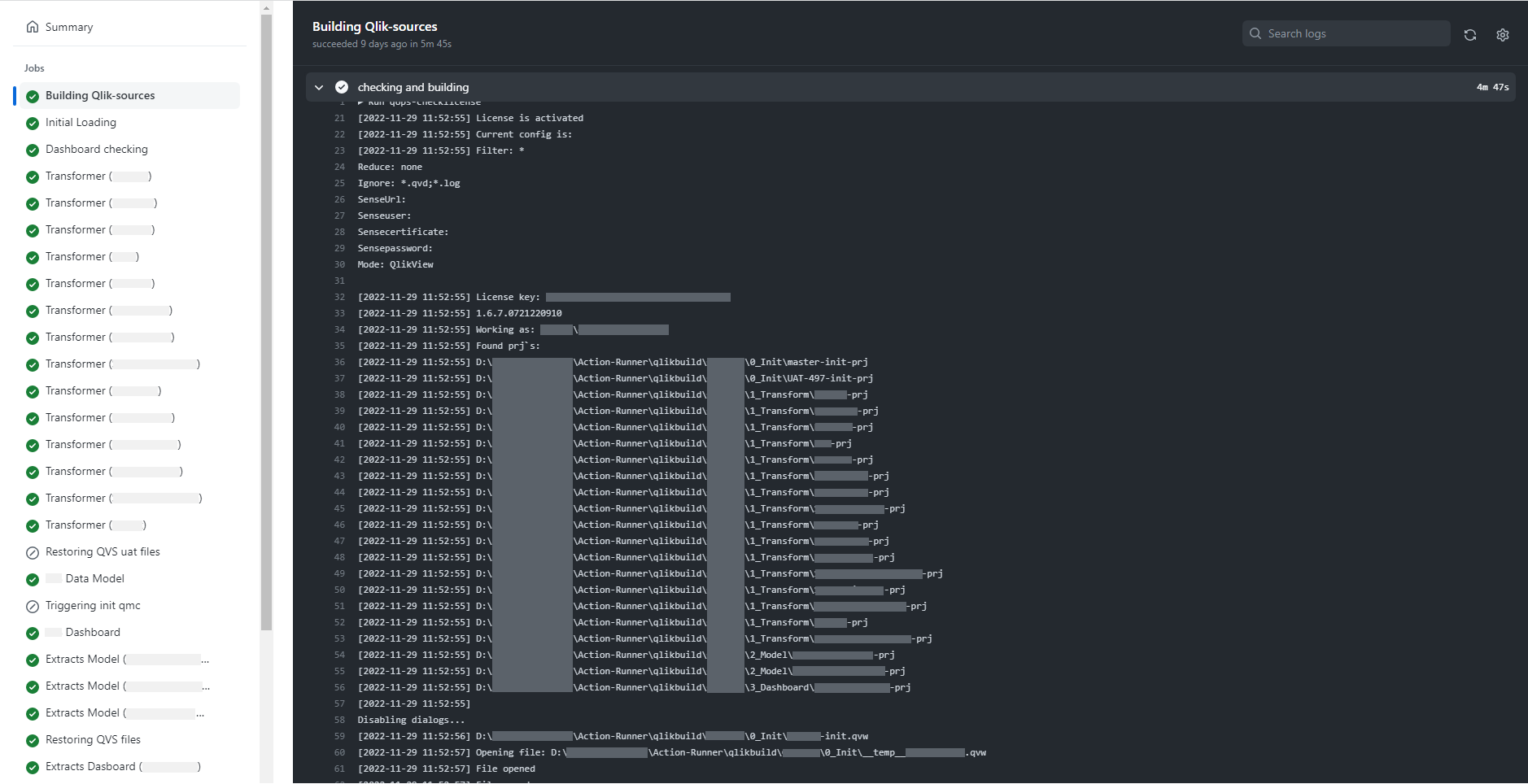
For a more detailed study of each execution step, console output is available at each stage. This makes it convenient to track and resolve errors that occur.
So, CI/CD introduction into Qlik application development and maintenance process has reduced the time spent on converging the results of parallel development and greatly simplified the process of preparing application files for further deployment.
More information about QOps at the link
Margin is down three points. The CFO knows that already. The dashboard told them, the board deck told them, the number is not in dispute. What they wa...
At some point, every BI team that grows past three or four developers hits the same moment. Deployment coordination starts eating senior time. Small i...
The Qlik ecosystem is at an inflection point. AI systems and automated pipelines are starting to consume analytics output as input, not just present i...
No comments yet.
Leave a comment