At some point, every BI team that grows past three or four developers hits the same moment. Deployment coordination starts eating senior time. Small incidents creep up. The process that worked fine with two people does not work with six. Something has to change, and the question becomes whether it is worth investing to change it.
This is written for the people who own that decision: the BI lead living it, and the director or owner who signs off on it. Not as a script for winning a budget meeting, but as an honest look at what the gap actually costs and what a sensible response looks like. If you decide it is not a priority yet, you should be able to reach that conclusion on the facts, not because someone framed it well.
So here is the situation, the three reasons it matters, the one reason that gets overstated, and a way to adopt it that keeps the risk small.
The most common way this gets sold internally is “we will save ten hours a week.” It is true, and it is the weakest reason to act.
Hours saved are real but hard to pin down, easy to argue about, and they frame the whole thing as a minor efficiency tweak. That framing undersells it. If the only problem were a few slow hours, you could reasonably wait. The reasons that actually justify the investment are about risk, about where your expensive people spend their time, and about whether your analytics layer can keep up with what the business is building on top of it. Hours saved is a bonus you notice after, not the case for doing it.
This is the one most organizations underestimate until it bites.
Almost every production incident in Qlik traces to the same root: a change nobody can see. There is no diff, no audit trail, no clean way to compare yesterday’s working app to today’s broken one. When a dashboard breaks, the team troubleshoots by guessing while the business waits. Recovery means finding a backup file somewhere and hoping it is recent.
Step back and this is unusual. Every other system the business depends on has change management of some kind: someone can answer “what changed, who changed it, and how do we undo it.” For the Qlik layer, which is often the system leadership looks at most, the honest answer is frequently “we are not sure.” That is not a developer convenience problem. It is an operational and governance gap, and it sits on the reporting everyone trusts to make decisions.
If you want to size it for yourself, three honest questions tell you most of what you need to know. How many production incidents in the last year came from a change nobody tracked? How long does an average one take to resolve when there is no diff and no rollback? And how many of your Qlik apps now feed something downstream, like automated reports or AI workflows that consume their output? The answers usually make the case better than any argument does.
A senior Qlik developer is an expensive hire, and a meaningful share of their week goes to work that does not require their skill: confirming who can deploy what and when, investigating what changed after an incident, manually moving apps between environments, and being the one person who cannot be away when something needs to ship.
The cost here is not the salary spent on those hours. It is the work that does not happen instead. The person who understands your revenue model because they built the data behind it is coordinating file transfers rather than sitting with Finance or Marketing improving the decisions those teams make. That is the actual loss, and it does not show up on any line in the budget.
There is a quieter cost too. Capable people get restless doing work that cannot be reviewed, leaves no record, and vanishes the moment it is done. Teams that still operate like deployment is a manual chore tend to lose their strongest engineers first, and replacing that knowledge is far more expensive than the tooling that would have kept it interesting.
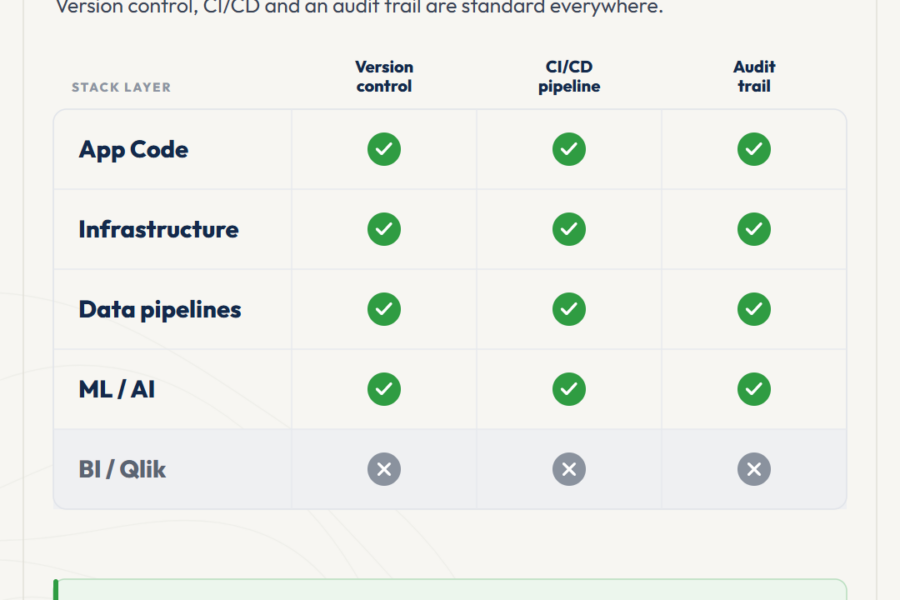
Look at how every other technical team in the organization already works:

This was tolerable when BI was a side output. It is becoming a real problem now, because more systems consume Qlik’s output directly. The moment an AI workflow or an automated report reads from a Qlik app, an untracked change to that app stops being an internal annoyance and becomes something that quietly breaks the things built on top of it. Investing in data and AI strategy while the layer underneath has no version control is building on a foundation you cannot inspect. Bringing Qlik up to the same engineering baseline as everything else is not adopting something exotic. It is closing a gap that the rest of the stack closed years ago.
None of this argues for a big transformation, and you should be suspicious of anyone who proposes one. The sensible path is small and reversible, and it also happens to be the most honest way to find out whether the benefit is real for your team.
Phase one, two weeks: pick one non-critical app with two or three developers and put it under version control. Branch, change, review, merge. No pipeline yet, just source control and a real diff.
Phase two, the following two weeks: add automated deployment for that one app, dev to test to production, with a manual approval gate before production.
Phase three, the following months: if it worked, expand to the remaining apps and train the wider team. If it did not, you stop, having spent very little.
The thing to evaluate is deliberately small: one app, two developers, two weeks, and a clear checkpoint at the end to expand or stop. Most tooling for this offers a trial or a guided pilot, so the upfront cost is usually close to zero. The point of starting small is not to make the request easier to approve. It is that a two-week pilot on your own apps gives you evidence instead of a promise, and evidence is what should drive the decision either way.
If your team is at the point where this question keeps coming up, it is usually because the gap is already costing something: incidents without a clear cause, senior people stuck on plumbing, or a growing unease that the reporting everyone relies on has less control around it than everything else you run. Those are real business problems, not tooling preferences, and they are worth weighing honestly.
If you want to see what a two-week pilot actually looks like on your own apps, we run 30-minute walkthroughs. Book one here.

No comments yet.
Leave a comment