
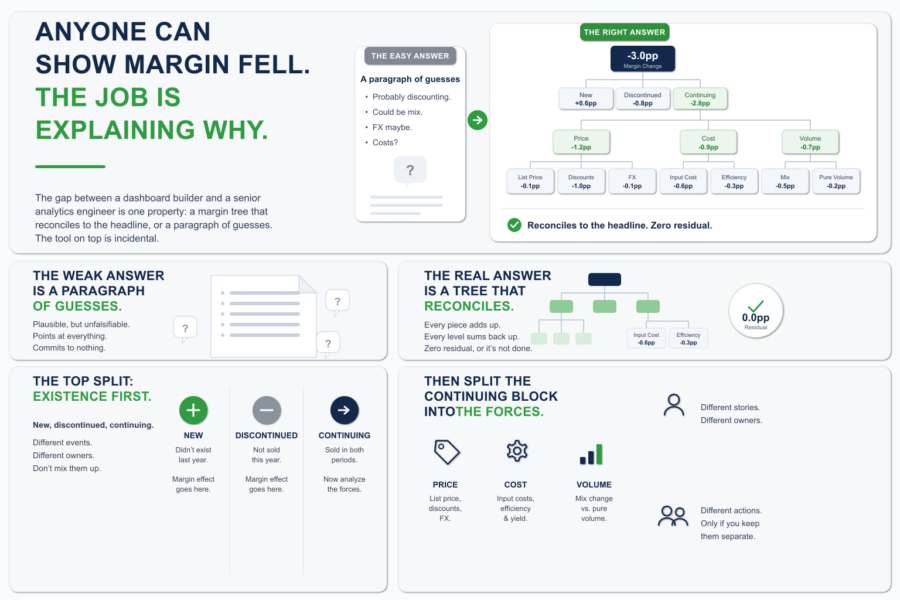
Anyone Can Show Margin Fell. The Job Is Explaining Why.
Margin is down three points. The CFO knows that already. The dashboard told them, the board deck told them, the number is not in dispute. What they wa...
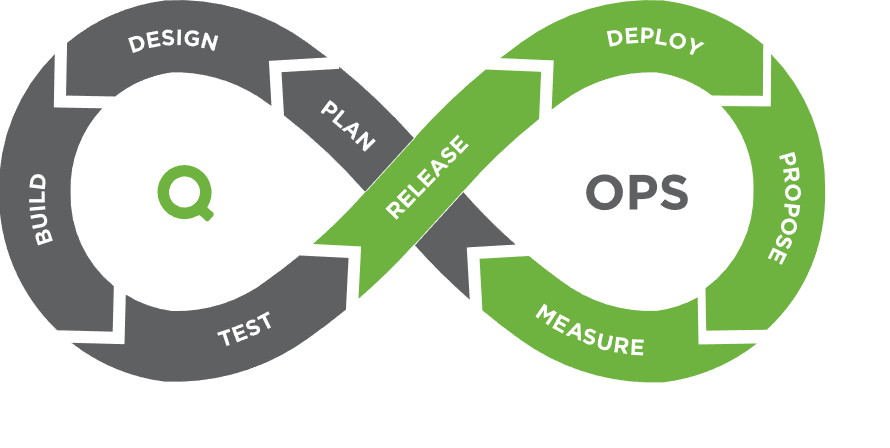
CI/CD pipelines help to minimize potential risks in the process of integrating code changes into the repository, isolate the impact of possible errors and simplify fixing process. The main CI/CD goal is to speed up development process and value delivery to the end user. However, there are always ways and tools to make the process even more efficient. The matrix approach is one such option.
The basic pipeline structure involves the execution of tasks simultaneously at a certain stage. Tasks at the next stage can be completed if the previous ones are completed. This process continues at all stages. Different tasks in a pipeline take different times to complete. So, team members must wait to make their changes to the project. This significantly slows down the workflow and reduces productivity. Also, the presence of the same pipelines and creation scripts can lead to pipelines blocking. To optimize resources and increase productivity, it makes sense to create tasks clones and run them in parallel.
Previously, it was necessary to manually define tasks for their parallel execution. With the advent of parallel matrix jobs, it became possible to create jobs at runtime based on specified variables.
The matrix strategy uses variables when defining a job and allows to provide automatic creation of multiple job executions. This strategy can be used in the process of testing code in different languages and/or different operating systems. The matrix can be created with different job configurations specifying one or more variables. By defining variables (one or more), task will be applied for each variable combination.
It is also worth considering one feature. So, organizations often use mono-repositories for better project management. However, pipeline performance is degraded when there are many projects in the repository and one pipeline definition is used to run different automated processes for different components. Using parent and child pipelines makes pipelines more efficient. This approach minimizes the chance of merge conflicts and allows editing of pipeline parts if necessary.
On the one hand, pipelines optimization reduces the time developers spend on maintenance. On the other hand, it frees up time and space for new ideas, creativity and increased productivity. For example, using a matrix, it is possible to break down large pipelines into manageable parts for more efficient maintenance and maximization of tasks amount that run in parallel. The order in which jobs are created dictates the order of the variables in the matrix. The first variable is the first job in the run.
The complex Qlik application architecture consists of several layers (transformers, model, dashboard and extractors). And when using QOps, the matrix strategy is the best suited for managing applications of the same type within the same layer. These include applications in the layer of transformers and extractors.
GitHub, GitLab and Jenkins allow to build pipelines based on a matrix strategy that iterates over the available tasks according to cartesian multiplication. This was done to expand CI/CD capabilities, namely in testing on different platforms or, for example, with different frameworks versions.
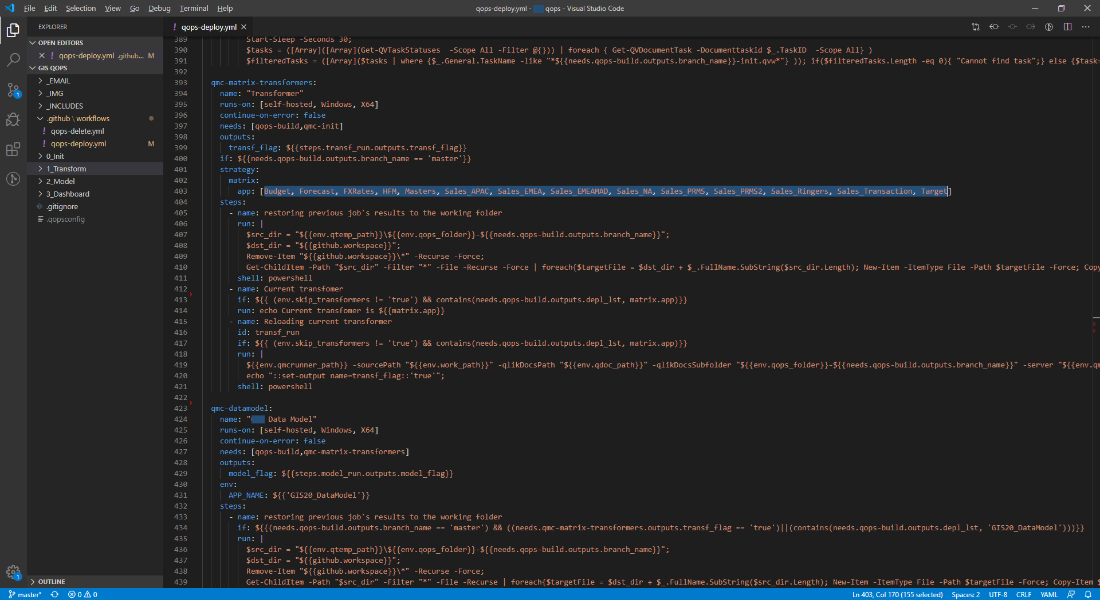
The screenshot below contains an example pipeline source file for GitHub, where transformer overloading is implemented using a matrix strategy. The keyword for this is matrix in strategy block. The required list of applications is specified as a list on line 403. In this case, the substitution of the iterated application will be performed each time matrix.app is specified.
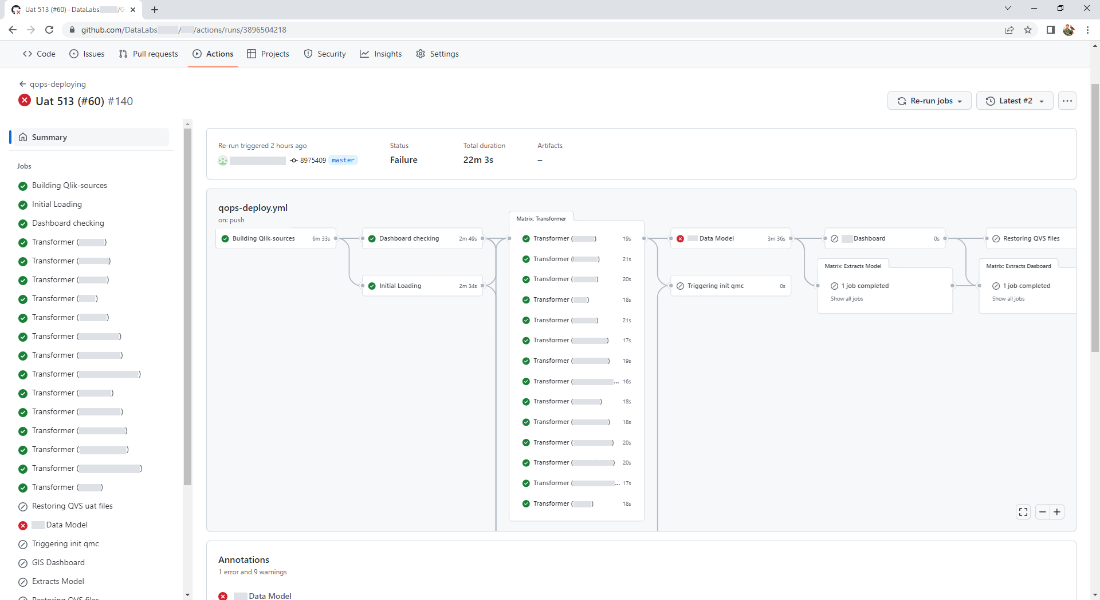
This is how used applications list in GitHub graphical interface looks like when executing the pipeline. At the same time, scaling the number of processed applications is easily performed. To do this, it is enough just to change their list and not make changes to the executable part of the code.
More information you will find at the link
Margin is down three points. The CFO knows that already. The dashboard told them, the board deck told them, the number is not in dispute. What they wa...
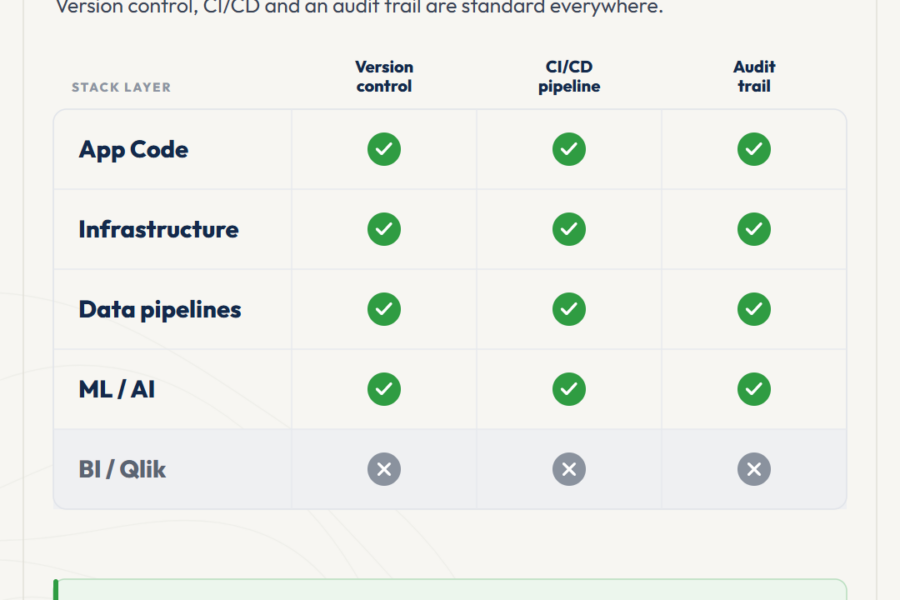
At some point, every BI team that grows past three or four developers hits the same moment. Deployment coordination starts eating senior time. Small i...
The Qlik ecosystem is at an inflection point. AI systems and automated pipelines are starting to consume analytics output as input, not just present i...
No comments yet.
Leave a comment