
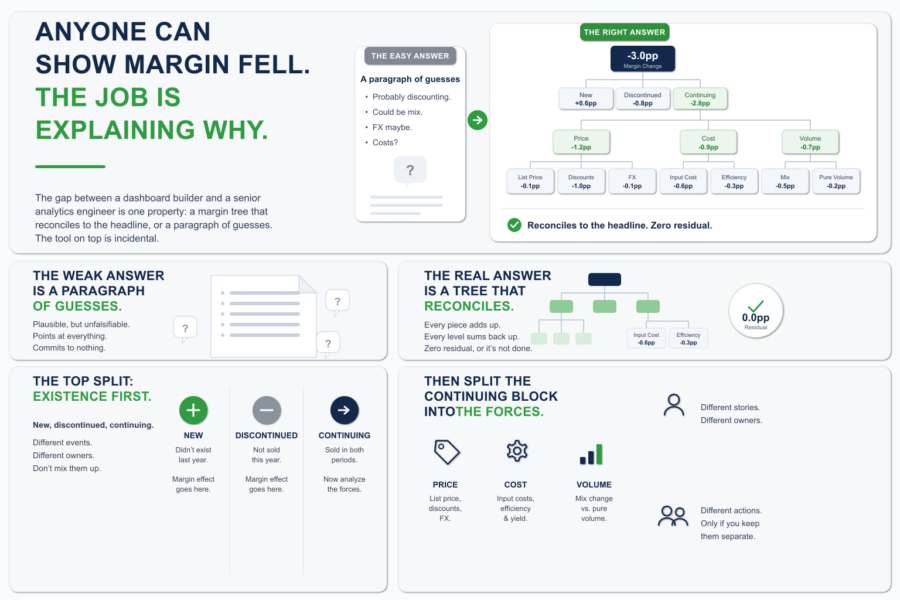
Anyone Can Show Margin Fell. The Job Is Explaining Why.
Margin is down three points. The CFO knows that already. The dashboard told them, the board deck told them, the number is not in dispute. What they wa...

Among other modern terms and concepts, the most relevant are machine learning (ML) and Big Data. These 2 terms are often used in conjunction, although they have a fundamental difference. And it is important to understand this difference during a data strategy development.
The similarity between machine learning and Big Data is that both terms refer to the field of theoretical academic research and practical data-driven business applications. It is a scientific discipline that studies information and use cases.
Data is the main engine of technological progress. It helps to create new tools and platforms to change the world through analytics, more accurate modeling and forecasting. The development of the Covid-19 vaccine is a great example of the data importance in today’s world. Usually, it took up to 10 years to develop a vaccine. However, over the past decade, the ability to collect and process data has expanded significantly. It has significantly accelerated the pace of vaccine development. If this pandemic had happened in 2010, it would have taken a lot longer to solve this problem, just because technologies for deep data understanding were in their infancy.
This situation is made possible by both Big Data and Machine Learning. Let’s make sense of the terms.
Big Data is a collective term that includes a huge amount of ever-growing information, as well as tools, methods and technologies that have been developed to work with data, including Machine Learning. With the Internet transformation into a daily use tool, Big Data has begun to be identified as a powerful tool. Big Data isn’t just about size. Data definition as big assumes the presence of 3 characteristics («3 V»):
Machine Learning is a type of computer algorithm. It can be viewed as part of Artificial Intelligence (AI). A fundamental aspect of intelligence is learning. Machine learning is involved in creating programs that help to perform better taking into account an ever-growing data amount.
It is important to understand the difference between supervised and unsupervised ML. Supervised learning is a Machine Learning technique that includes tagged learning algorithms that lets you know immediately how well an operation has been performed. Unsupervised learning is a method of Machine Learning, as a result of what the system under test spontaneously learns to perform tasks.
Big data and Machine Learning are intertwined. The best results are most likely to be obtained by using the most appropriate ML and Big Data processes.
However, if the business does not work with Big Data, Machine Learning is unlikely to be needed. Its main advantage is the extraction of value from datasets that are difficult for classical computer and statistical analysis. For example, for a static dataset that fits into an Excel worksheet, the ML implementation will not be justified. It is advisable to use this tool in the case of working with unstructured data that cannot be understood using tables (text, graphic, sound data etc).
Margin is down three points. The CFO knows that already. The dashboard told them, the board deck told them, the number is not in dispute. What they wa...
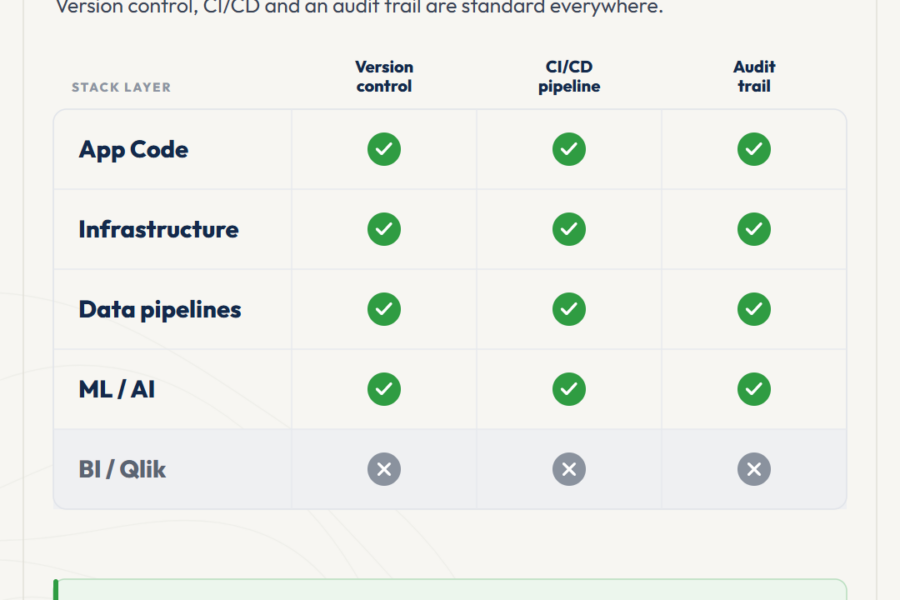
At some point, every BI team that grows past three or four developers hits the same moment. Deployment coordination starts eating senior time. Small i...
The Qlik ecosystem is at an inflection point. AI systems and automated pipelines are starting to consume analytics output as input, not just present i...
No comments yet.
Leave a comment