
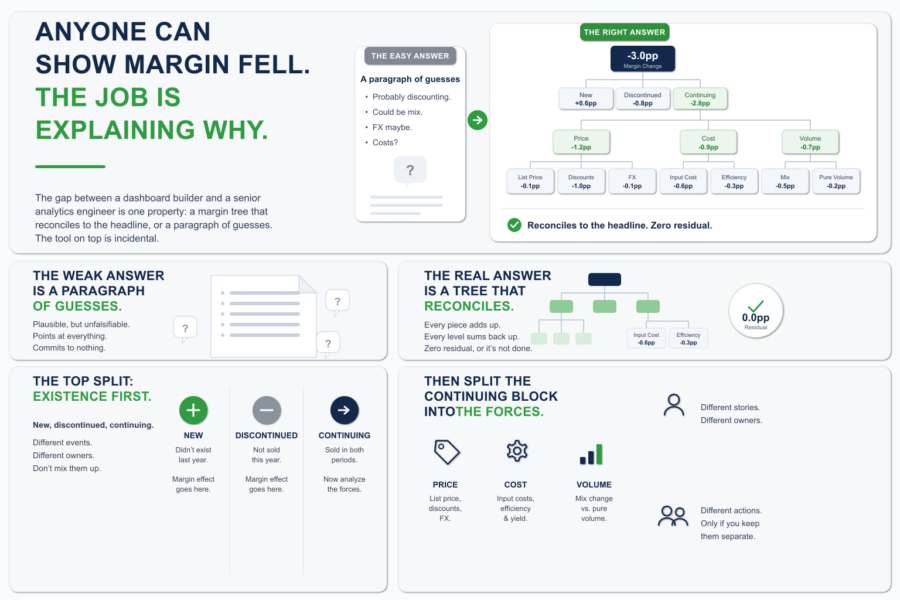
Anyone Can Show Margin Fell. The Job Is Explaining Why.
Margin is down three points. The CFO knows that already. The dashboard told them, the board deck told them, the number is not in dispute. What they wa...

Another one trend is data lake and data warehouse combine that promotes data stack simplification. Until recent times data lake and data warehouse subsist separately. Both objects are intended to data holding. But they are not synonymous and there is a principal difference between them.
The first object is a repository for a big volume of raw data in its original form from different sources. Data can be of different types: structured, semi-structured and unstructured. Data lake is characterized by high data flexibility and availability and a big choice oh machine learning usage.
The second object is also a repository for a big volume of data. But in this case data runs processing and gets into the storage already structured strictly regulated ways. Data warehouse is characterized by less flexibility, fixed configuration and transactional analytics and BI support.
Wishing to get the best of both sides, organizations try to combine 2 variants. As a result, they have both data lake and data warehouse (sometimes several with many parallel pipelines). Today’s data storage solution providers offer more such possibilities. For example, Snowflake – its platform allows to connect data warehouse and data lake; Microsoft Synapse – its cloud warehouse has integrated capabilities of data lake.
Margin is down three points. The CFO knows that already. The dashboard told them, the board deck told them, the number is not in dispute. What they wa...
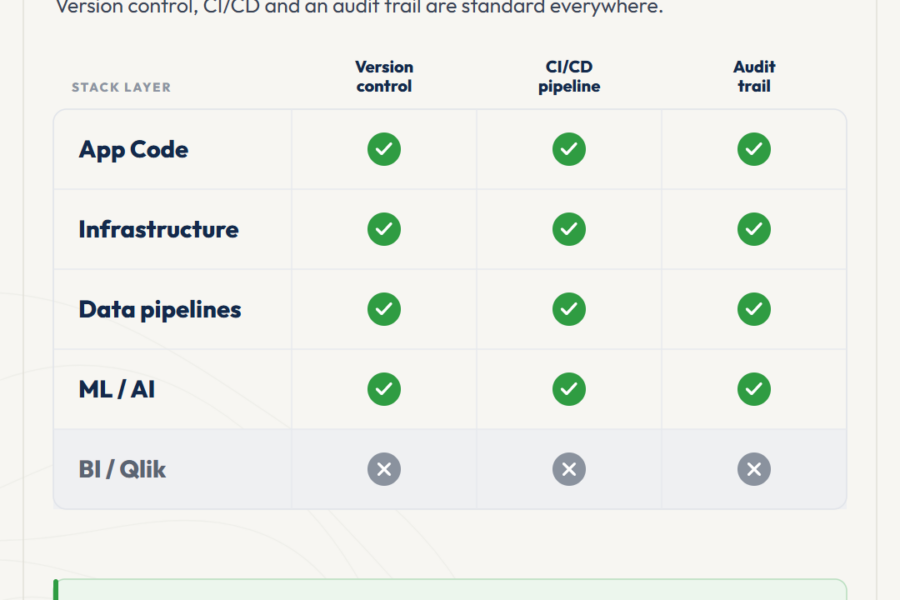
At some point, every BI team that grows past three or four developers hits the same moment. Deployment coordination starts eating senior time. Small i...
The Qlik ecosystem is at an inflection point. AI systems and automated pipelines are starting to consume analytics output as input, not just present i...
[…] Попередній пост #maindatainfrastructuretrends […]