
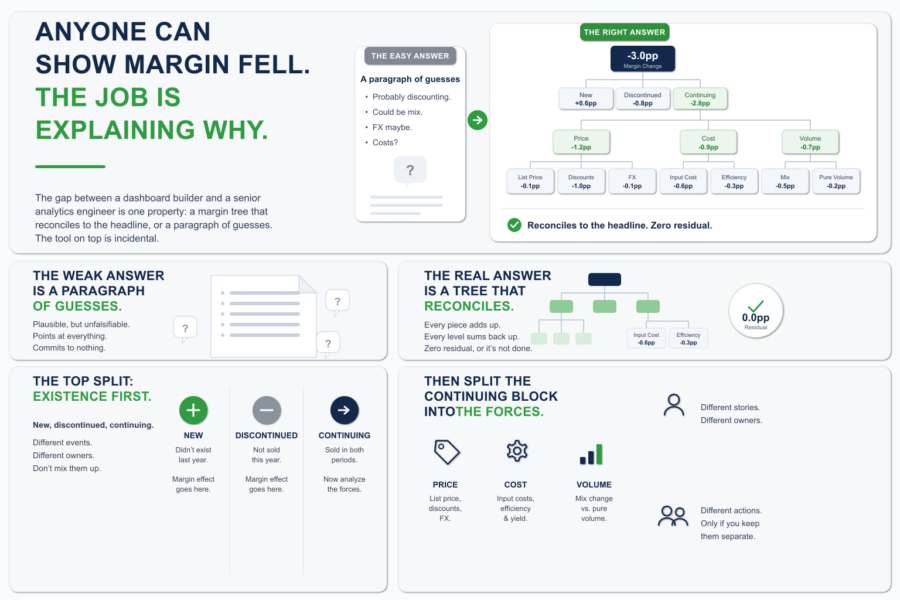
Anyone Can Show Margin Fell. The Job Is Explaining Why.
Margin is down three points. The CFO knows that already. The dashboard told them, the board deck told them, the number is not in dispute. What they wa...

Modern companies often deal with large and complex data sets from different and possibly unrelated data sources (CRM, IoT, streaming data, marketing automation, finance, etc.). Large companies often have branches in different geographic locations. This can complicate the process of data using or storing (in the cloud, hybrid multicloud, on-premises, etc.). Data Fabric will help to combine data from different sources and repositories, transform and process it for further work. As a result, users get a holistic picture of the current situation, that allows them to explore and analyze data to conduct effective business activities.
Data Fabric is a data integration architecture using metadata assets to unify, integrate, and manage disparate data environments. The main task of Data Fabric is to structure the data environment, and it doesn’t require replacement of existing infrastructure. Metadata and data access are managed by adding an additional technology layer over the existing infrastructure. Standardizing, connecting, and automating of Data Fabric data management practices improves data security and availability, enables end-to-end integration of data pipelines and on-premises cloud, hybrid multicloud, and edge device platforms.
Benefits of Data Fabric using:
Data Fabric simplifies a distributed data environment where they it can be received, transformed, managed, stored. It also defines access for multiple repositories and use cases (BI tools, operational applications. This is made possible by continuous metadata analytics to build the web layer. It integrates data processing processes and many sources, types, and locations of data.
Differences Data Fabric from the standard data integration ecosystem:
The Data Fabric architecture depends on individual data needs and queries of business. However, there are 6 main levels:
When implementing Data Fabric, you need to consider:
DataLabs is a Qlik Certified Partner. A high level of team competence and an individual approach allows to find a solution in any situation. You can get additional information by filling out the form at the link
Margin is down three points. The CFO knows that already. The dashboard told them, the board deck told them, the number is not in dispute. What they wa...
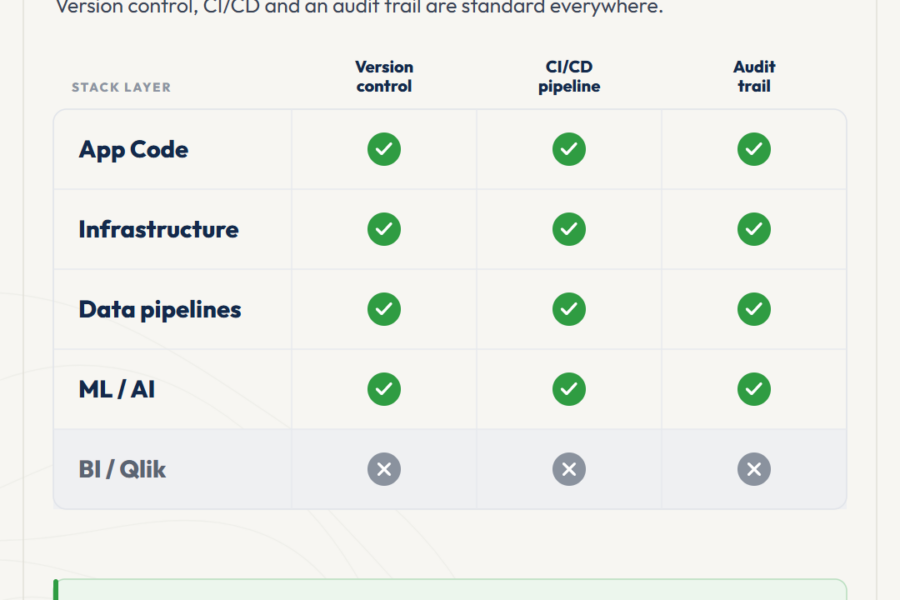
At some point, every BI team that grows past three or four developers hits the same moment. Deployment coordination starts eating senior time. Small i...
The Qlik ecosystem is at an inflection point. AI systems and automated pipelines are starting to consume analytics output as input, not just present i...
No comments yet.
Leave a comment